XGBoost e SA-GA: La Combo Vincente per Svelare i Segreti della Permeabilità nelle Rocce Carbonatiche!
Ciao a tutti gli appassionati di geoscienze e tecnologia! Oggi voglio parlarvi di una sfida affascinante che mi ha tenuto incollato allo schermo (e ai dati!) per un bel po’: come diavolo facciamo a prevedere quanto un giacimento di idrocarburi in rocce carbonatiche sia… beh, *permeabile*? Sembra una domanda semplice, ma credetemi, quando si ha a che fare con queste rocce, le cose si complicano parecchio.
Il Dilemma della Permeabilità nelle Rocce Carbonatiche
Immaginate le rocce carbonatiche come spugne incredibilmente complesse e capricciose. A differenza delle rocce clastiche (come le arenarie, più “ordinate”), quelle carbonatiche presentano una eterogeneità pazzesca. I pori, cioè gli spazi vuoti dove si accumulano petrolio e gas, possono avere forme e dimensioni diversissime, e la loro connessione (la permeabilità, appunto!) è spesso un vero rompicapo. La classica relazione tra porosità (quanto spazio vuoto c’è) e permeabilità (quanto facilmente i fluidi ci passano attraverso) qui salta completamente. Puoi avere rocce molto porose ma poco permeabili, e viceversa. Un incubo per chi deve decidere dove perforare!
I metodi tradizionali, spesso presi in prestito dallo studio delle rocce clastiche o basati su formule empiriche, mostrano la corda. I risultati sono spesso deludenti e poco affidabili. Serviva qualcosa di più potente, di più “intelligente”. Ed è qui che entra in gioco il meraviglioso mondo dell’intelligenza artificiale e del machine learning.
La Potenza di XGBoost: Un Algoritmo con i Muscoli
Negli ultimi anni, abbiamo visto un’esplosione nell’uso di algoritmi di machine learning per interpretare i dati geofisici, in particolare i dati di logging (le misurazioni fatte nei pozzi). Abbiamo provato con reti neurali (come le BP), alberi decisionali (come il C5.0), foreste casuali… tutti hanno dato qualche risultato, ma spesso si incappa in problemi come lentezza, tendenza all’overfitting (cioè imparare troppo bene i dati di training e fallire su quelli nuovi) o eccessiva complessità.
Poi è arrivato XGBoost (eXtreme Gradient Boosting). Ragazzi, questo algoritmo è una forza della natura! È una versione potenziata del Gradient Boosting Decision Tree (GBDT), ma con alcuni assi nella manica:
- È efficiente: sfrutta il processore al massimo con calcoli paralleli.
- È scalabile: gestisce grandi quantità di dati senza battere ciglio.
- È preciso: grazie a un’ottimizzazione matematica più raffinata (espansione di Taylor al secondo ordine sulla funzione di perdita, per i più tecnici!).
- È robusto: include termini di regolarizzazione che evitano l’overfitting e controllano la complessità del modello.
Insomma, sembrava l’attrezzo giusto per il nostro lavoro sporco sulla permeabilità.

L’Ingrediente Segreto: Ottimizzazione SA-GA
Ma c’è un “ma”. Anche un algoritmo potente come XGBoost ha bisogno di essere “tarato” alla perfezione. Ha un sacco di parametri interni (iperparametri, li chiamiamo noi nerd) che devono essere impostati correttamente: il numero di alberi decisionali, il tasso di apprendimento, i coefficienti di regolarizzazione, la profondità massima degli alberi… Impostarli a caso o basandosi solo sull’esperienza non garantisce il miglior risultato.
Ecco che abbiamo pensato: perché non usare un altro algoritmo intelligente per ottimizzare il primo? Qui entra in scena la nostra arma segreta: un algoritmo ibrido chiamato SA-GA, che sta per Simulated Annealing – Genetic Algorithm. Mamma mia, che nomi! Ma l’idea è geniale:
- L’Algoritmo Genetico (GA) si ispira all’evoluzione naturale: crea una “popolazione” di possibili set di parametri, li fa “accoppiare” (crossover) e “mutare”, selezionando le combinazioni migliori. È veloce a convergere verso buone soluzioni.
- Il Simulated Annealing (SA) si ispira al processo di raffreddamento lento dei metalli (ricottura simulata): permette all’algoritmo di esplorare più a fondo lo spazio delle soluzioni, accettando anche soluzioni temporaneamente peggiori per evitare di rimanere bloccato in un ottimo locale (un picco minore invece della vetta più alta).
Mettendoli insieme, l’SA-GA combina la velocità del GA con la capacità dell’SA di trovare la soluzione *veramente* ottimale (l’ottimo globale). È come avere una squadra di esploratori veloci guidati da un saggio stratega che non si accontenta della prima collina che trova, ma cerca la montagna più alta!
Mettiamolo alla Prova: Il Caso Studio Cinese
Per testare questa super-combo SA-GA-XGBoost, abbiamo preso di mira un caso reale e bello tosto: i giacimenti carbonatici della Formazione Longwangmiao nel blocco Moxi del giacimento di gas di Anyue, nel bacino del Sichuan, in Cina. Parliamo di rocce antichissime, super eterogenee, con litologie varie (dolomiti a grana fine-media, a volte con strutture residue sabbiose o oolitiche) e tipi di pori diversi (intergranulari, intercristallini, cavità, fratture). Un vero parco giochi per la complessità!
Il nostro piano d’azione è stato:
- Selezione dei Dati Giusti: Abbiamo preso i dati di logging (misure fatte nei pozzi) e i dati di permeabilità misurati direttamente sui campioni di roccia (core data). Non tutte le curve di logging sono ugualmente utili. Usando tre diversi coefficienti di correlazione (Pearson, Kendall, Spearman), abbiamo identificato le 5 curve più “sensibili” alla permeabilità per questo giacimento: CNL (Neutron Porosity), DEN (Density), DT (Acoustic Transit Time), ln(RT) (Logaritmo della Resistività) e GR (Gamma Ray).
- Preparazione dei Dati: Abbiamo “normalizzato” i dati per metterli tutti sulla stessa scala (un passaggio fondamentale nel machine learning) e abbiamo trasformato logaritmicamente la curva di resistività.
- Addestramento e Ottimizzazione: Abbiamo diviso i nostri dati (200 campioni da 10 pozzi): 80% per addestrare il modello (160 campioni) e 20% per testarlo (40 campioni). Abbiamo lanciato l’algoritmo SA-GA per trovare i parametri ottimali per XGBoost (numero di alberi, tasso di apprendimento, ecc.). L’ottimizzazione ha richiesto circa mezz’ora, trovando i valori migliori dopo circa 120 iterazioni.
- Creazione del Modello Finale: Con i parametri ottimizzati, abbiamo costruito il nostro modello SA-GA-XGBoost definitivo.

I Risultati Parlano Chiaro: SA-GA-XGBoost Batte Tutti!
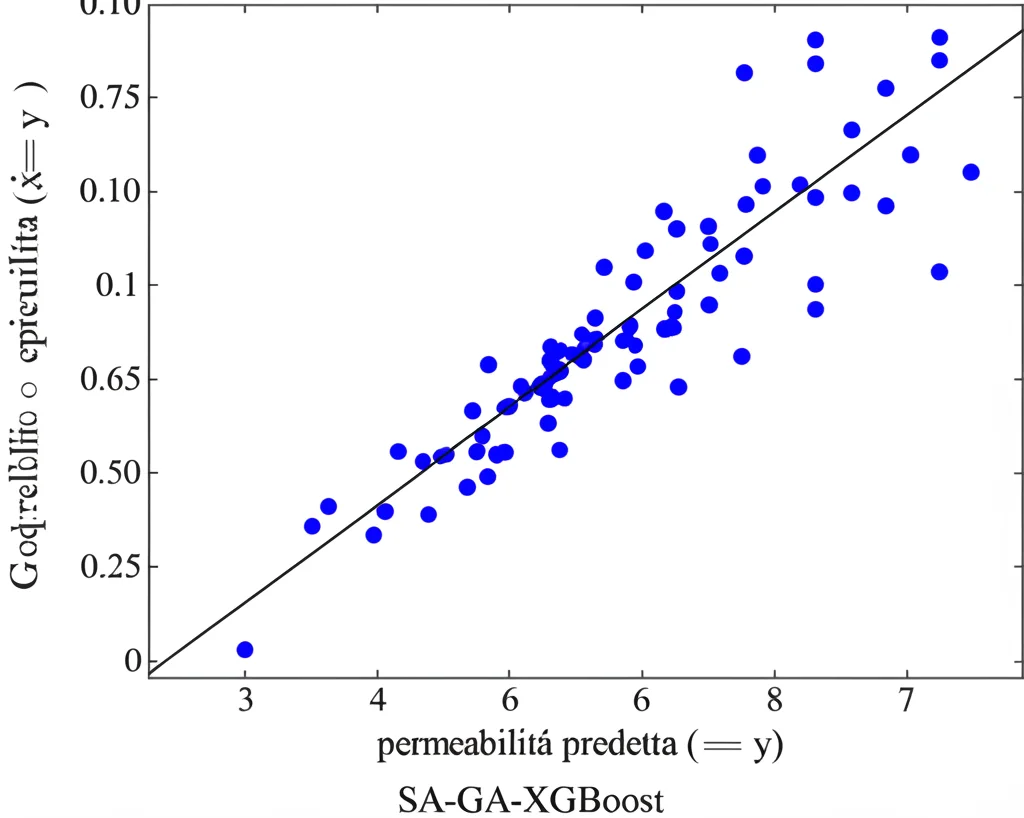
E ora, il momento della verità! Abbiamo usato il modello per predire la permeabilità sui 40 campioni di test che avevamo tenuto da parte. I risultati sono stati entusiasmanti!
- Il nostro modello SA-GA-XGBoost ha ottenuto un coefficiente di determinazione aggiustato (Adjusted R²) di 0.876 e un errore quadratico medio (RMSE) di appena 0.142. Tradotto: le previsioni erano dannatamente vicine ai valori reali misurati sui campioni!
- Per confronto, abbiamo provato anche un XGBoost “normale” (senza ottimizzazione SA-GA) sugli stessi dati: Adjusted R² di 0.774 e RMSE di 0.215. L’ottimizzazione ha fatto una bella differenza!
- Abbiamo anche confrontato il nostro modello con i metodi più tradizionali (la classica relazione porosità-permeabilità) e con una rete neurale BP (Back Propagation) su un pozzo specifico (M8). Beh, non c’è stata storia. Il metodo tradizionale era molto meno preciso (Adjusted R²=0.672, RMSE=0.364). La rete BP faceva meglio (Adjusted R²=0.738, RMSE=0.253), ma il nostro SA-GA-XGBoost li ha superati entrambi, mostrando una corrispondenza eccellente con i dati reali, specialmente nelle zone a bassa permeabilità, che sono spesso le più difficili da valutare.
Per essere sicuri che il modello non fosse solo bravo con quei dati specifici, abbiamo fatto anche una validazione incrociata (10-fold cross-validation), che ha confermato la sua robustezza e capacità di generalizzare.
Cosa Ci Riserva il Futuro?
Cosa ci portiamo a casa da questa avventura? Che combinare la potenza di XGBoost con l’intelligenza dell’ottimizzazione SA-GA ci permette di costruire modelli di predizione della permeabilità per rocce carbonatiche complesse che sono precisi, stabili e affidabili. Abbiamo dimostrato che selezionare attentamente le curve di logging più informative e ottimizzare finemente gli iperparametri dell’algoritmo fa davvero la differenza.
Questo approccio non solo migliora la valutazione dei giacimenti esistenti, ma apre nuove strade per l’esplorazione di petrolio e gas in queste formazioni geologiche così ostiche. E perché fermarsi qui? Penso che questo tipo di modello potrebbe essere applicato anche ad altri problemi geologici complessi, come l’identificazione delle fratture naturali nelle rocce.
Insomma, l’unione tra conoscenza geologica e algoritmi intelligenti è una frontiera entusiasmante, e non vedo l’ora di vedere quali altre scoperte ci riserverà!
Fonte: Springer