
SPHN Schema Forge: La Magia che Trasforma i Dati Sanitari da Geroglifici a Linguaggio Universale!
Ammettiamolo, navigare nel mondo dei dati sanitari a volte sembra come cercare di decifrare antichi geroglifici. Informazioni vitali, sparse in mille formati diversi, sistemi che non parlano tra loro, e una montagna di lavoro manuale per cercare di dare un senso a tutto. Un vero incubo per chiunque lavori nella ricerca o nella gestione sanitaria! Ma se vi dicessi che esiste uno strumento, una sorta di “fucina” magica, capace di trasformare questo caos in un ordine comprensibile sia agli umani che, soprattutto, alle macchine? Ebbene sì, sto parlando dello SPHN Schema Forge, un’innovazione che sta cambiando le carte in tavola nella gestione della semantica sanitaria.
La Sfida: Un Puzzle Chiamato Dati Sanitari
In Svizzera, come in molti altri posti, i dati sanitari provengono da una miriade di fonti: ospedali, laboratori, studi medici. Ognuno con i suoi standard, i suoi sistemi di valutazione della qualità, persino le sue lingue. Armonizzare e integrare questi dati per la ricerca è una vera impresa. Per raggiungere la tanto agognata interoperabilità – ovvero far sì che sistemi diversi possano scambiarsi e utilizzare informazioni in modo efficace – serve una struttura solida e semanticamente ricca. È qui che entra in gioco la Swiss Personalized Health Network (SPHN). L’SPHN ha sviluppato un Framework di Interoperabilità Semantica, guidato dai principi FAIR (Findable, Accessible, Interoperable and Reusable – Rintracciabili, Accessibili, Interoperabili e Riutilizzabili). Al centro di questo framework c’è l’SPHN Dataset, un foglio di calcolo strutturato che definisce la semantica sanitaria. Bello, no? Ma c’è un “ma”.
Questo Dataset, pur essendo un ottimo punto di partenza e comprensibile a medici, data manager e ricercatori (chi non conosce Excel?), ha i suoi limiti. Rappresentare relazioni complesse e gerarchie in tabelle è difficile, e le tabelle non sono facilmente processabili dalle macchine. Per superare questi ostacoli, l’SPHN ha abbracciato le tecnologie del Semantic Web. Immaginate il Web Semantico come un’estensione del web che conosciamo, dove le informazioni non sono solo presentate, ma anche *comprese* dalle macchine. Tecnologie come il Resource Description Framework (RDF) permettono di modellare i dati come un grafo di conoscenza, fatto di triple (soggetto-predicato-oggetto), molto più espressivo di una semplice tabella.
Il problema? Tradurre manualmente il Dataset SPHN, pensato per la lettura umana, in questo formato RDF, comprensibile alle macchine, era un processo lungo, laborioso e soggetto a errori. E qui, amici miei, la storia si fa interessante.
La Soluzione: Nasce SPHN Schema Forge!
Per automatizzare e snellire questa traduzione, è stato sviluppato lo SPHN Schema Forge. Pensatelo come un artigiano digitale super efficiente. Con pochi click, questo servizio web prende il vostro foglio di calcolo SPHN Dataset e lo trasforma in uno schema RDF. Ma non finisce qui! Genera anche:
- Regole SHACL (Shapes Constraint Language) per la validazione dei dati (per assicurarci che i dati siano conformi allo schema).
- Una visualizzazione HTML dello schema (perché anche l’occhio vuole la sua parte e per facilitare la comprensione umana).
- Query SPARQL (SPARQL Protocol and RDF Query Language) per analisi di base dei dati.
In pratica, riduce drasticamente lo sforzo manuale e il tempo necessario, permettendo ai ricercatori di concentrarsi su compiti più significativi, come l’interpretazione e l’analisi dei dati. Niente male, vero?

Dentro la Fucina: Come Funziona la Magia?
L’SPHN Schema Forge non è nato dal nulla. È il risultato di un approccio iterativo e centrato sull’utente, ispirato ai principi Agile. Si è partiti dalle esigenze concrete degli stakeholder:
- Un processo di modellazione semplificato per concetti e attributi specifici del progetto.
- Vincoli di validazione definiti per scovare errori di modellazione.
- Un set di query statistiche di base, pronte all’uso.
- Una visualizzazione user-friendly dello schema RDF.
Inizialmente sono nate soluzioni separate, poi fuse e integrate in questo servizio web.
Alla base di tutto c’è l’SPHN Dataset. Questo foglio di calcolo .xlsx è la “fonte della verità”. Deve rispettare una struttura predefinita, con diverse schede (tab):
- Guideline: introduce il Dataset.
- License: le licenze applicabili.
- Release Notes: i cambiamenti tra le versioni.
- Metadata: metadati per lo schema RDF (prefisso, titolo, descrizione, ecc.). Questo è cruciale per i principi FAIR!
- Coding System and Version: elenca i sistemi di codifica o standard esterni referenziati (es. SNOMED CT, ICD-10-GM, ATC). Per sfruttare appieno i principi dei linked data, è ideale che queste terminologie siano disponibili in RDF.
- Concepts: il cuore pulsante! Qui vengono elencati tutti i concetti e i loro attributi. Ogni riga rappresenta un concetto (una classe) o un suo attributo (composedOf), con colonne che specificano dettagli come il “parent” (concetto genitore da cui ereditare attributi), la cardinalità (se un attributo è obbligatorio o meno), e i “value set” (i valori ammessi, magari da un sottogruppo di una terminologia standard).
Prendiamo un esempio: il concetto ‘Billed Diagnosis’ (Diagnosi Fatturata). Nel Dataset si specifica che eredita dal concetto più generico ‘Diagnosis’, che ha un attributo ‘code’ che usa la codifica ICD-10-GM, un attributo ‘record datetime’ (obbligatorio), e così via.
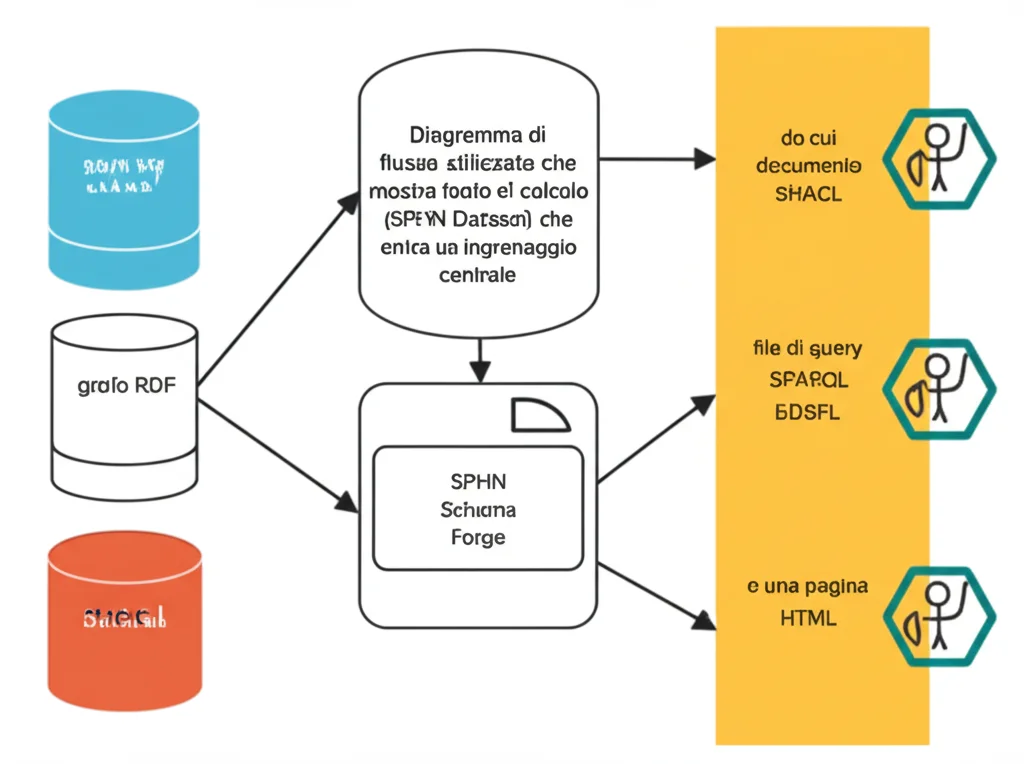
Lo SPHN Schema Forge prende queste informazioni, in particolare dalle schede ‘Metadata’, ‘Coding System and Version’ e ‘Concepts’, e le processa. È importante sottolineare che la conversione dal Dataset allo schema RDF è un processo a senso unico. Non si può ricostruire perfettamente il Dataset originale dall’RDF, perché alcune informazioni potrebbero essere consolidate o astratte.
Il “motore” dello SPHN Schema Forge è composto da tre strumenti principali:
- SPHN Dataset2RDF: È il componente chiave che trasforma il Dataset in formato .xlsx nel suo schema RDF corrispondente. Utilizza Python e la libreria RDFLib, traducendo le righe della scheda ‘Concepts’ in costrutti RDF, RDFS e OWL (Web Ontology Language, che offre un linguaggio ancora più ricco per definire significati e relazioni). Ad esempio, un concetto diventa una owl:Class, la sua etichetta una rdfs:label, la sua definizione uno skos:definition, e le restrizioni di cardinalità o sui valori diventano owl:Restriction.
- SPHN SHACLer: Questo script Python genera automaticamente le forme SHACL partendo dallo schema RDF. SHACL è un linguaggio per validare grafi RDF. Lo SHACLer opera con un’assunzione di “mondo chiuso” (tipica per i dati dei pazienti, dove ogni record è considerato completo durante la validazione). Crea diverse tipologie di vincoli SHACL, ad esempio per verificare le cardinalità (sh:minCount, sh:maxCount), i tipi di dati, o che i valori provengano da specifici sistemi di codifica.
- SPHN Schema Doc: Basato su pyLODE, questo strumento genera due output preziosi: una documentazione HTML dello schema RDF (per una facile consultazione umana, con tanto di funzione di ricerca e visualizzazione tabellare delle restrizioni) e query SPARQL statistiche. Queste query (flattening, conteggio di codici, conteggio di istanze, min-max) permettono ai ricercatori di ottenere insight preliminari sui loro dati.
L’Impatto: Meno Fatica, Più Scienza!
Lo SPHN Schema Forge è un servizio web accessibile gratuitamente (codice sorgente su GitLab sotto licenza GPLv3). Dal 2022, l’SPHN Data Coordination Center (DCC) lo usa per ogni rilascio dello SPHN RDF Schema, riducendo il tempo di creazione da giorni a minuti! Anche i quattro flussi di dati nazionali svizzeri (Malattie Infettive, Oncologia, Pediatria, Cure di Qualità) lo usano per estendere il Dataset SPHN con la loro semantica specifica.
Questo strumento è un enorme vantaggio, specialmente per chi non è un esperto di tecnologie del Semantic Web. Certo, l’esperienza umana con conoscenza del dominio rimane fondamentale per garantire l’accuratezza semantica e la fattibilità. L’automazione permette di concentrarsi meglio sulla semantica e sull’arricchimento dell’SPHN Dataset. La governance del Dataset è un processo collaborativo tra l’SPHN DCC e il Semantics Working Group, composto da esperti. Vengono rilasciate nuove versioni annualmente.
Per i progetti che estendono il Dataset, l’SPHN DCC fornisce formazione, documentazione e supporto. L’obiettivo è evitare la frammentazione semantica e promuovere l’integrazione a lungo termine delle estensioni.
Qualità dei Dati e Sguardo al Futuro
Avere dati di alta qualità è cruciale. Lo SPHN SHACLer aiuta a garantire la conformità allo schema RDF. Ad esempio, se l’unità di misura per la saturazione di ossigeno deve essere una percentuale, lo SHACLer lo verifica. Tuttavia, altri aspetti della qualità dei dati, come la correttezza (il peso e l’altezza di un paziente sono plausibili?), l’accuratezza (una diagnosi di “cancro” è meno precisa di “carcinoma duttale invasivo”) o la completezza (la data di nascita è completa o c’è solo l’anno?), non sono coperti automaticamente e possono richiedere personalizzazioni SHACL da parte dei progetti.
Lo SPHN Schema Forge, quindi, non è solo un pezzo di software. È un abilitatore. Semplificando la generazione di artefatti semantici, rende più facile per i progetti creare schemi e dati conformi ai principi FAIR e scambiabili. Questo ha il potenziale di contribuire agli sforzi più ampi per l’interoperabilità dei dati sanitari, ben oltre i confini svizzeri.
Certo, la modellazione dei dati e la definizione della semantica sottostante rimangono processi manuali, che richiedono tempo e competenza. Gli sviluppi futuri potrebbero esplorare possibilità di validazione automatica della qualità e una migliore interazione con l’utente in queste aree. Ma per ora, il pacchetto completo prodotto dallo SPHN Schema Forge aiuta enormemente sia i processi di creazione che di consumo dei dati. È un passo avanti gigantesco per armonizzare e utilizzare i dati nel panorama sanitario svizzero, gettando solide basi per future iniziative nella gestione semantica dei dati. E chissà, magari un giorno, grazie a strumenti come questo, decifrare i dati sanitari sarà facile come leggere un libro aperto!
Fonte: Springer





