Sussurri Lontani: Come l’IA Impara ad Ascoltarci Meglio (e con Meno Sforzo!)
Ciao a tutti! Avete presente quando cercate di parlare con il vostro assistente vocale dall’altra parte della stanza, magari con la TV accesa o i bambini che giocano? Ecco, quella è la sfida del riconoscimento vocale a campo lontano (Far-Field Speech Recognition, o FSR per gli amici). Nonostante i passi da gigante fatti dall’intelligenza artificiale nel capire la nostra voce, rumore di fondo, eco e semplice distanza possono ancora mandare in tilt i nostri dispositivi smart.
Negli ultimi anni sono emersi modelli potentissimi, pre-addestrati su quantità enormi di dati, come il famoso Whisper di OpenAI. Questi “cervelloni” digitali sono bravissimi in tante cose, ma adattarli specificamente a capire i nostri comandi sussurrati da lontano presenta due grossi problemi:
- Costi Elevati: Riadattare (fare il “fine-tuning”) questi modelli giganti richiede un sacco di tempo e potenza di calcolo (e quindi energia!).
- Rischio Overfitting: I segnali vocali da lontano sono spesso “sporchi” e con poche informazioni utili (basso rapporto segnale-rumore). Addestrare un modello enorme su questi dati rischia di fargli imparare a memoria i disturbi specifici di quel set di dati, invece di generalizzare bene. Diventa troppo “fissato” sui dati di training e poi performa male in situazioni nuove.
Insomma, serviva un modo più furbo ed efficiente.
L’Idea Geniale: Adattamento Efficiente Senza Svuotare il Portafoglio (né il Pianeta!)
Qui entrano in gioco le tecniche di fine-tuning efficiente in termini di parametri (Parameter-Efficient Fine-Tuning, PEFT). L’idea di base è semplice: invece di modificare l’intero, gigantesco modello pre-addestrato, congeliamo la maggior parte dei suoi parametri (i “mattoni” interni del modello) e addestriamo solo una piccola parte aggiuntiva o modifichiamo leggermente il modo in cui il modello processa l’input. È come aggiungere delle piccole manopole di regolazione a un motore potentissimo, invece di smontarlo e rimontarlo da capo.
Tra queste tecniche, noi abbiamo deciso di esplorare qualcosa di relativamente nuovo nel campo del parlato, ispirato dal mondo del linguaggio naturale: il prompting. Invece di cambiare il modello, si “suggerisce” al modello cosa fare tramite degli input speciali, chiamati “prompt”.
Ecco SPT: Accordare l’IA con dei “Prefissi” Vocali
Per affrontare le sfide dell’FSR, abbiamo introdotto per la prima volta (sì, siamo stati i primi a farlo per l’FSR!) una tecnica chiamata Speech Prefix Tuning (SPT), basata sul modello Whisper. Immaginatela così: invece di modificare i pesi interni del modello, aggiungiamo delle piccole sequenze di vettori (i “prefissi”, appunto, come delle note musicali speciali) all’input di ogni strato del modello. Questi prefissi sono gli unici elementi che vengono imparati durante l’addestramento. Il modello Whisper originale rimane intatto, congelato.
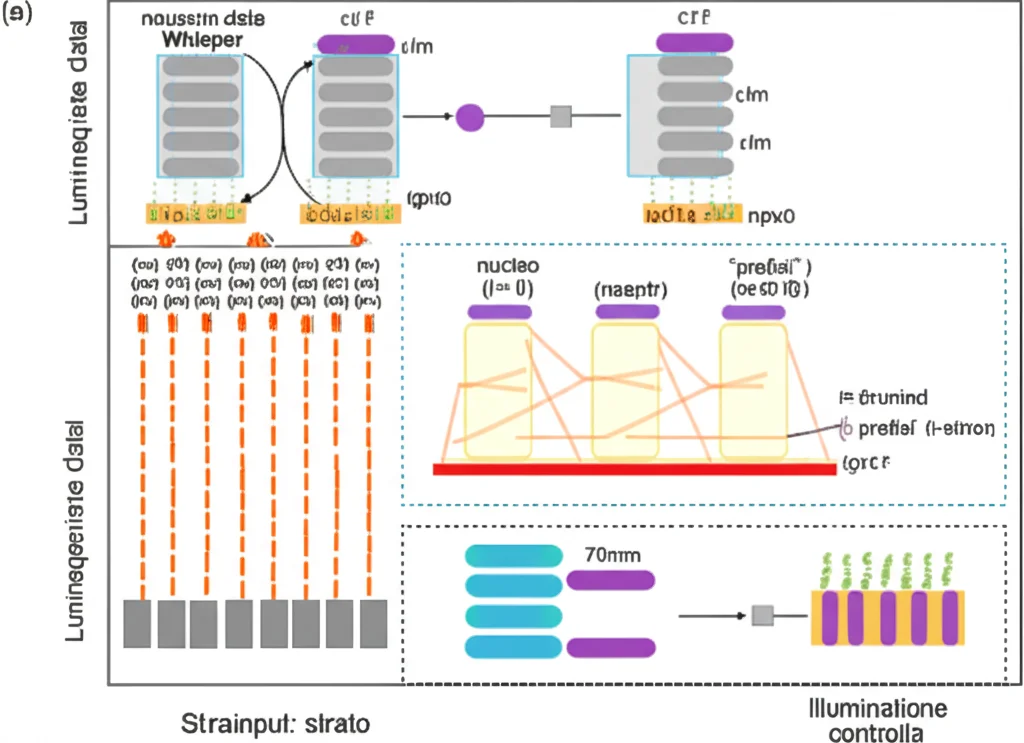
Questo approccio ha diversi vantaggi:
- Super Efficiente: Si addestrano pochissimi parametri rispetto al fine-tuning completo o anche ad altre tecniche PEFT come LoRA (Low-Rank Adaptation).
- Pratico e Trasferibile: I “prefissi” imparati sono piccoli e possono essere facilmente salvati e scambiati per adattare il modello a compiti diversi o a utenti specifici.
- Migliora l’Interpretabilità: Analizzando questi prefissi, possiamo capire meglio come il modello si sta adattando.
Nei nostri esperimenti sul dataset DiPCo (che simula una cena rumorosa), SPT ha battuto LoRA, ottenendo un tasso di errore sulle parole (Word Error Rate, WER) relativamente inferiore del 5.76%, usando addirittura meno parametri! Niente male, vero?
Il Problema dei Microfoni Multipli: Come Farli Andare d’Accordo con MCAT
Un’altra bella gatta da pelare nell’FSR, specialmente in ambienti come case o sale riunioni, è l’uso di più microfoni (spesso disposti in array). Ogni microfono, a causa della sua posizione, cattura il suono in modo leggermente diverso, con rumori di fondo e riverberi unici. Questo crea un’ “interferenza di canale”: lo stesso discorso suona diverso a seconda del microfono che lo registra. Come possiamo insegnare all’IA a ignorare queste differenze e concentrarsi solo sul contenuto del parlato?
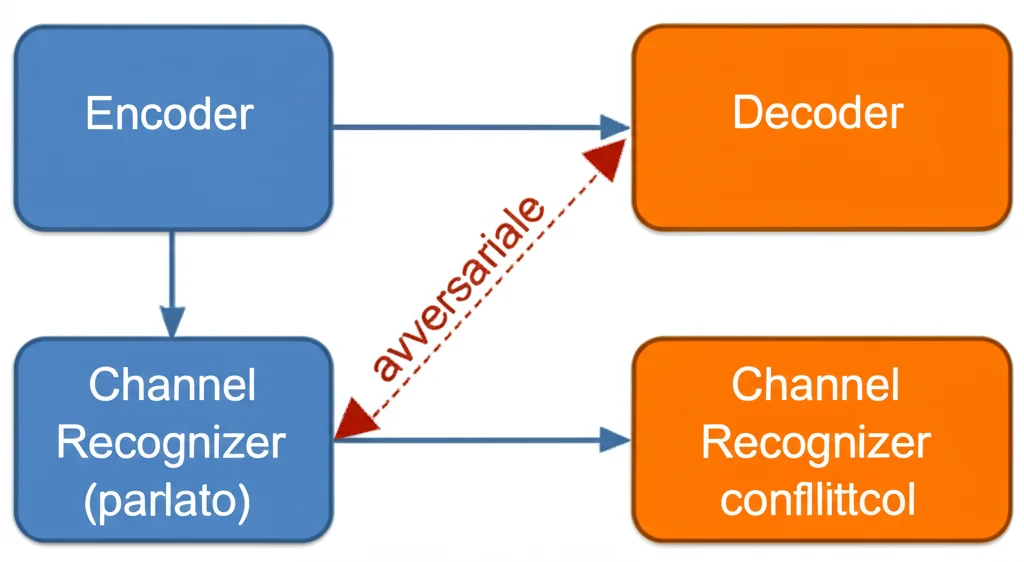
Qui abbiamo tirato fuori dal cilindro l’Addestramento Avversariale Multi-Canale (Multi-Channel Adversarial Training, MCAT). L’idea è un po’ come un gioco tra guardie e ladri. Abbiamo aggiunto un piccolo “riconoscitore di canale” che cerca di indovinare da quale microfono proviene il segnale audio processato dall’encoder del modello Whisper. Contemporaneamente, addestriamo l’encoder di Whisper non solo a riconoscere il parlato (minimizzando l’errore WER), ma anche a *ingannare* il riconoscitore di canale (massimizzando l’errore del riconoscitore).
In pratica, l’encoder viene “spinto” a produrre rappresentazioni del parlato che siano il più possibile indipendenti dal canale, rendendo difficile per il riconoscitore capire da quale microfono provengono. È un po’ come insegnare a qualcuno a parlare con un accento neutro, in modo che non si capisca da dove viene.
Alla Prova dei Fatti: Esperimenti e Risultati
Abbiamo testato le nostre idee (SPT e MCAT, applicato sia a SPT che a LoRA) su due dataset impegnativi:
- DiPCo: Simula una cena di famiglia registrata con 5 dispositivi dotati di array microfonici (35 microfoni in totale!).
- CHiME-6: Registrazioni di vere cene con più partecipanti in ambienti domestici, usando 6 dispositivi Kinect (24 microfoni) e microfoni indossati dai partecipanti.
I risultati sono stati davvero incoraggianti. Su DiPCo, come già detto, SPT ha superato LoRA. L’aggiunta di MCAT ha ulteriormente ridotto il WER sia per LoRA (riduzione relativa del 3.92% su Whisper-Large-v2) sia per SPT (riduzione relativa del 3.71% su Whisper-Large-v2), dimostrando che aiuta il modello a gestire meglio le differenze tra i canali.
Sul dataset CHiME-6, la situazione è stata un po’ più sfumata. LoRA a volte ha funzionato meglio di SPT, forse perché SPT è più sensibile alle differenze tra i dati di addestramento (DiPCo) e quelli di test (CHiME-6). Tuttavia, SPT ha mostrato i muscoli con i modelli Whisper più grandi (Large-v3), confermando l’idea che i prompt funzionano meglio quando c’è più “potenza” nel modello base da sbloccare. Ma la cosa più importante è che MCAT ha migliorato le prestazioni in modo consistente su tutti i modelli e su entrambi i metodi (LoRA e SPT) anche su CHiME-6, dimostrando la sua capacità di generalizzare e migliorare la robustezza del riconoscimento indipendentemente dal dataset specifico.
Uno Sguardo Dentro l’IA: Visualizzare l’Effetto di MCAT
Per capire meglio cosa succede “sotto il cofano”, abbiamo usato una tecnica di visualizzazione chiamata t-SNE per osservare le rappresentazioni interne del parlato generate dall’encoder di Whisper, prima e dopo l’addestramento con MCAT. Abbiamo colorato i punti in base al canale microfonico di provenienza.
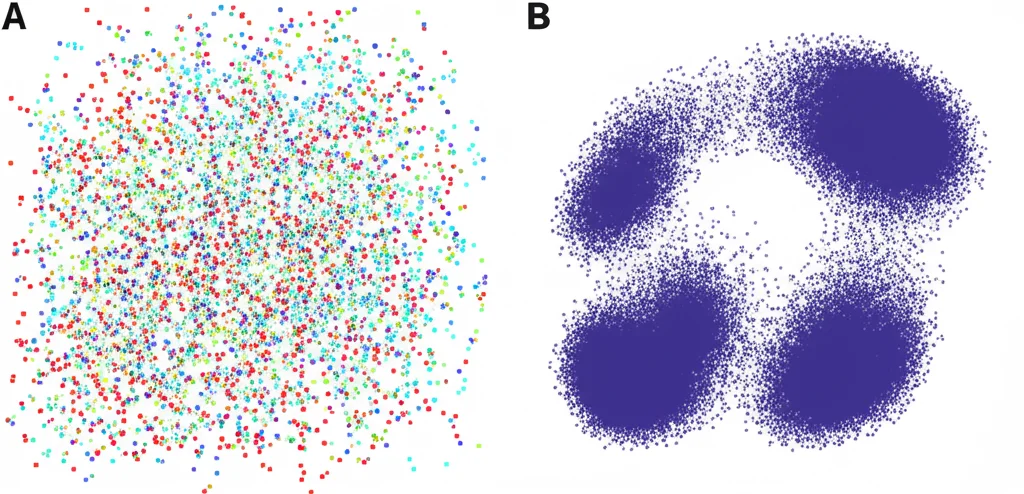
I risultati sono stati chiari: senza MCAT, le rappresentazioni dello stesso parlato proveniente da canali diversi erano abbastanza sparse e distinte. Con MCAT, invece, queste rappresentazioni tendevano a raggrupparsi molto di più, diventando più simili indipendentemente dal microfono. Questo conferma visivamente che MCAT sta facendo il suo lavoro: sta aiutando il modello a imparare caratteristiche del parlato che sono invarianti rispetto al canale, riducendo l’impatto negativo delle differenze tra i microfoni. Abbiamo anche misurato la “dispersione” (varianza) di questi gruppi, trovando che era significativamente più bassa con MCAT (0.8 contro 1.62 del baseline), un’ulteriore prova quantitativa.
Conclusioni e Prossimi Passi
Quindi, cosa ci portiamo a casa? Abbiamo dimostrato che lo Speech Prefix Tuning (SPT) è un modo promettente ed efficiente per adattare modelli potenti come Whisper al difficile compito del riconoscimento vocale a campo lontano, superando spesso alternative come LoRA con meno parametri. Inoltre, abbiamo introdotto l’Addestramento Avversariale Multi-Canale (MCAT) come strumento efficace per combattere l’interferenza tra i canali microfonici, migliorando ulteriormente le prestazioni e la generalizzazione del modello.
Questi approcci aprono la strada a sistemi di riconoscimento vocale più robusti, efficienti e capaci di capirci meglio anche quando siamo lontani o in ambienti rumorosi. Il prossimo passo? Esplorare queste tecniche con modelli auto-supervisionati ancora più potenti. La sfida di farci capire dall’IA, anche quando sussurriamo da lontano, continua!
Fonte: Springer