
Previsioni Fluviali Potenziate: Sfruttare Dati Multi-Sorgente e Deep Learning Accoppiato
Ciao a tutti! Oggi voglio parlarvi di qualcosa che mi appassiona molto e che ritengo fondamentale per il nostro futuro: come possiamo prevedere meglio il comportamento dei nostri fiumi, specialmente in un’epoca di cambiamenti climatici così rapidi. Immaginate di poter sapere con largo anticipo quanta acqua scorrerà in un fiume, non solo per prevenire disastrose alluvioni, ma anche per gestire al meglio le siccità, ottimizzare l’uso delle risorse idriche per l’agricoltura o la produzione di energia idroelettrica, e persino per proteggere i nostri delicati ecosistemi fluviali. Sembra fantascienza? Beh, ci stiamo avvicinando, e voglio raccontarvi come.
La Sfida: Prevedere l’Imprevedibile
Prevedere il deflusso dei fiumi, specialmente a medio e lungo termine (parliamo di mesi!), è un rompicapo incredibile. Il motivo? Il deflusso è il risultato di un mix complicatissimo di fattori: le piogge, l’evaporazione, la neve che si scioglie, la forma del terreno, il tipo di suolo, la vegetazione e, sempre di più, le attività umane. Aggiungeteci poi l’influenza dei grandi sistemi climatici globali, come le oscillazioni atmosferiche e oceaniche (avete mai sentito parlare di El Niño?), che chiamiamo indici di teleconnessione. Questi indici sono come dei segnali che ci arrivano da lontano e che possono influenzare il meteo locale, e quindi il deflusso, anche a distanza di tempo.
I metodi tradizionali, spesso basati su statistiche classiche, fanno fatica a gestire tutta questa complessità. Hanno difficoltà a “digerire” dati provenienti da tante fonti diverse (multi-sorgente), a capire le relazioni non lineari (quelle dove causa ed effetto non sono proporzionali) e a districarsi tra variabili che magari dicono cose simili (multicollinearità) o che sono semplicemente troppe (alta dimensionalità). Il risultato? Previsioni spesso poco accurate o instabili.
La Nostra Idea: Unire le Forze con Modelli Accoppiati
Di fronte a questa sfida, abbiamo pensato: perché non combinare il meglio di due mondi? Da un lato, la potenza della statistica per “pulire” i dati e selezionare solo le informazioni davvero utili. Dall’altro, la flessibilità dell’apprendimento automatico (Machine Learning) e dell’apprendimento profondo (Deep Learning), che sono bravissimi a scovare pattern nascosti e relazioni complesse nei dati, anche quelle non lineari.
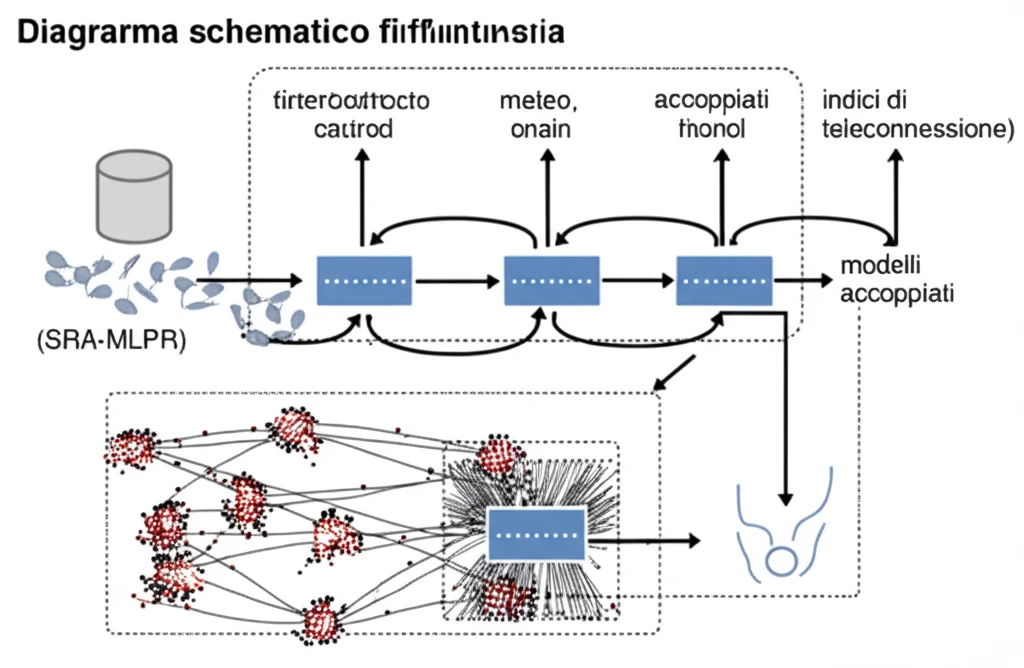
Così sono nati i nostri due “campioni”: i modelli accoppiati SRA-SVR e SRA-MLPR. Cosa significano queste sigle astruse?
- SRA (Stepwise Regression Analysis): È il nostro “selezionatore”. Prima di dare i dati in pasto ai modelli più complessi, usiamo la SRA per scegliere, passo dopo passo, solo le variabili (inclusi i famosi indici di teleconnessione) che hanno un impatto reale sul deflusso, eliminando quelle ridondanti o che creano confusione. È come fare ordine prima di iniziare un lavoro complicato.
- SVR (Support Vector Regression): È un robusto algoritmo di machine learning, particolarmente bravo a gestire relazioni non lineari usando delle “funzioni kernel”, anche quando non abbiamo tantissimi dati.
- MLPR (Multi-Layer Perceptron Regression): Questo è il nostro pezzo da novanta del deep learning. È una rete neurale artificiale con più strati, capace di “imparare” da sola le caratteristiche più profonde e nascoste nei dati, eccellendo con grandi quantità di informazioni e alta dimensionalità.
L’idea è semplice: SRA prepara il terreno selezionando gli ingredienti giusti, e poi SVR o MLPR cucinano la previsione finale, sfruttando al massimo le informazioni selezionate.
Il Potere Nascosto degli Indici di Teleconnessione
Una delle chiavi del nostro approccio è stato l’uso massiccio degli indici di teleconnessione. Abbiamo considerato ben 80 diversi indici di circolazione atmosferica! Perché sono così importanti? A differenza dei dati meteo locali (come la pioggia di ieri), questi indici riflettono dinamiche climatiche su larga scala che si sviluppano *prima* che i loro effetti si manifestino localmente. Sono come un’avvisaglia, un indicatore anticipato di ciò che potrebbe succedere.
Abbiamo scoperto, analizzando i dati, che l’influenza di questi indici sul deflusso non è immediata. C’è un ritardo. E indovinate qual è il ritardo ottimale che abbiamo trovato per il nostro caso di studio? Un mese! Questo significa che guardando agli indici atmosferici di un mese fa, possiamo avere un’idea più precisa del deflusso di oggi. Una scoperta fondamentale per migliorare le previsioni a medio-lungo termine!
Il Banco di Prova: Il Bacino del Fiume Yalong
Per mettere alla prova i nostri modelli, avevamo bisogno di un’area complessa, un vero test sul campo. Abbiamo scelto il Bacino del Fiume Yalong (YLRB), in Cina. È un bacino enorme, con paesaggi diversissimi, dalle alte montagne del Kunlun fino a zone subtropicali, influenzato da monsoni e circolazioni d’alta quota. Insomma, un sistema idrologico complicato, perfetto per vedere se i nostri modelli erano all’altezza. Abbiamo usato i dati storici di deflusso mensile (dal 1953 al 2011) di quattro stazioni idrologiche lungo il fiume (Lianghekou, Jinping, Guandi, Ertan) e li abbiamo incrociati con gli 80 indici atmosferici.
I Risultati: Un Salto di Qualità nelle Previsioni
Ebbene, i risultati sono stati davvero incoraggianti!
- I modelli accoppiati battono quelli singoli: Confrontando i nostri SRA-SVR e SRA-MLPR con i modelli SVR e MLPR usati da soli (come baseline), abbiamo visto un netto miglioramento. Il nostro campione, l’SRA-MLPR, è stato eccezionale: ha ridotto l’errore quadratico medio (RMSE) del 26% e l’errore percentuale assoluto medio (MAPE) del 34% rispetto ai modelli base. Inoltre, ha migliorato l’efficienza di Nash-Sutcliffe (NSE, un indice che misura quanto il modello è migliore della semplice media storica) del 13%, avvicinandosi molto di più al valore ideale di 1.
- Eccellenza negli estremi: L’SRA-MLPR si è dimostrato particolarmente bravo a prevedere i picchi di piena e i periodi di magra, che sono gli eventi più critici da gestire.
- Stabilità e Indici Climatici: L’inclusione degli indici di teleconnessione non solo ha arricchito le informazioni a disposizione, ma ha reso i modelli più stabili e capaci di catturare quelle relazioni nascoste e non lineari che governano il deflusso.
In pratica, combinando la selezione intelligente delle variabili (SRA) con la potenza del deep learning (MLPR) e nutrendo il tutto con dati climatici su larga scala (indici di teleconnessione), siamo riusciti a fare un bel passo avanti nella precisione delle previsioni.

Aprire la “Scatola Nera”: Capire il Perché con SHAP
Uno dei problemi del machine learning, e soprattutto del deep learning, è che a volte sono come delle “scatole nere”: funzionano bene, ma non capiamo esattamente *perché* prendono certe decisioni. Per un campo come la gestione delle risorse idriche, dove le decisioni hanno impatti enormi, la trasparenza è fondamentale.
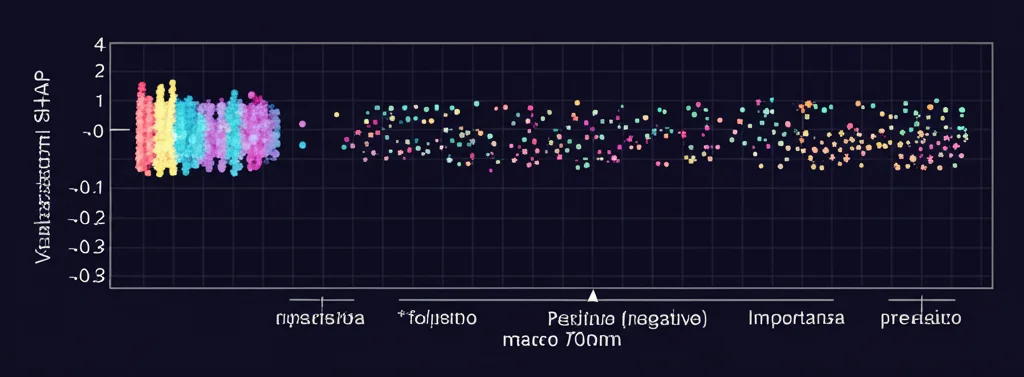
Qui entra in gioco un altro strumento fantastico: SHAP (SHapley Additive exPlanations). È una tecnica presa in prestito dalla teoria dei giochi che ci permette di “interrogare” il modello e capire quanto ogni singola variabile di input (nel nostro caso, ogni indice atmosferico) ha contribuito a una specifica previsione. È come dare un punteggio di importanza a ciascun giocatore (variabile) per il risultato finale della partita (la previsione).
Grazie a SHAP, abbiamo potuto vedere nero su bianco quali sono i “pezzi grossi” del clima che influenzano di più il deflusso nel bacino dello Yalong. I risultati sono stati illuminanti:
- Il Vortice Polare dell’Emisfero Nord e l’Intensità della Saccatura dell’Asia Orientale sono risultati i fattori dominanti. Le loro variazioni hanno un impatto enorme sul trasporto di aria fredda e umida, e quindi sulle precipitazioni e sul deflusso.
- Anche altre oscillazioni su larga scala, come l’Oscillazione Nord Atlantica (NAO) e l’Oscillazione Decadale del Pacifico (PDO), giocano un ruolo importante, modulando l’influenza dei fattori principali.
- Le interazioni non sono semplici! SHAP ci ha mostrato che l’effetto di un indice può cambiare a seconda del valore di un altro indice. Ad esempio, l’effetto del Vortice Polare può essere amplificato o smorzato a seconda dello stato della Saccatura dell’Asia Orientale. Questo conferma la complessità del sistema climatico e l’importanza di modelli capaci di catturare queste interazioni non lineari.
Questa analisi non solo aumenta la nostra fiducia nei modelli, ma ci fornisce anche preziose informazioni fisiche sui meccanismi che legano clima e idrologia.
Perché Tutto Questo è Importante?
Ok, abbiamo modelli più precisi e più interpretabili. E allora? Beh, le implicazioni sono enormi.
- Gestione del Rischio Idrogeologico: Previsioni migliori significano allerte più tempestive per le piene, permettendo evacuazioni e misure di protezione più efficaci. Significano anche una migliore pianificazione per affrontare periodi di siccità.
- Ottimizzazione delle Risorse Idriche: Sapere in anticipo quanta acqua arriverà permette di gestire meglio i serbatoi per la produzione di energia idroelettrica, per l’irrigazione agricola e per l’approvvigionamento idrico delle città.
- Adattamento ai Cambiamenti Climatici: Capire come i grandi pattern climatici influenzano i fiumi è cruciale per sviluppare strategie di adattamento efficaci in un clima che cambia.
- Scalabilità: I nostri modelli sono progettati per essere modulari e adattabili. Questo significa che l’approccio può essere potenzialmente applicato ad altri bacini fluviali nel mondo, con caratteristiche climatiche e geografiche diverse.
Stiamo fornendo strumenti più potenti e affidabili per prendere decisioni informate sulla gestione di una risorsa preziosa e vitale come l’acqua.
Guardando al Futuro
Certo, c’è ancora strada da fare. Una limitazione attuale è che i nostri modelli si concentrano principalmente sui fattori naturali, mentre l’impatto delle attività umane (cambiamenti nell’uso del suolo, urbanizzazione, prelievi idrici) è ancora difficile da quantificare e integrare pienamente. Inoltre, vogliamo rendere i modelli ancora più “auto-interpretabili”, in modo che la spiegazione del loro funzionamento sia intrinseca al modello stesso.
Ma la direzione è chiara: l’integrazione di dati multi-sorgente, la potenza degli approcci accoppiati di machine/deep learning e l’attenzione all’interpretabilità rappresentano una frontiera promettente per l’idrologia e le scienze ambientali. In un mondo che affronta sfide idriche sempre più pressanti, credo che questo tipo di ricerca sia non solo affascinante, ma assolutamente necessario. Spero di avervi trasmesso un po’ della mia passione!
Fonte: Springer





