
PLGNN: Viaggio nel Cuore delle Reti Neurali per Grafi con Link Autostradali e Perturbazioni Adattive!
Amici appassionati di intelligenza artificiale e dati complessi, oggi voglio portarvi con me in un’esplorazione affascinante nel mondo delle Reti Neurali per Grafi (GNN). Immaginate di avere una mappa intricatissima di relazioni, come una rete social, una rete di citazioni scientifiche o persino le interazioni tra proteine nel nostro corpo. Le GNN sono gli strumenti magici che ci permettono di dare un senso a tutto questo, scovando pattern e connessioni nascoste. Ma, come in ogni avventura che si rispetti, ci sono delle sfide. E qui entra in gioco un approccio davvero brillante chiamato PLGNN, acronimo di Graph Neural Networks via Adaptive Feature Perturbation and High-way Links. Preparatevi, perché stiamo per scoprire come rendere le nostre GNN ancora più potenti!
Il Cruccio delle GNN: Informazioni Mancanti e il Fantasma dell’Overfitting
Le GNN, nella loro essenza, funzionano aggregando informazioni dai nodi vicini in un grafo per aggiornare le caratteristiche (features) di un nodo specifico. Pensatela come un passaparola intelligente: ogni nodo impara dai suoi “amici”. Questo processo, chiamato message-passing o aggregazione di vicinato, è potentissimo. Tuttavia, i dati del mondo reale sono spesso disordinati e incompleti. Cosa succede se nella nostra mappa mancano delle strade cruciali (gli archi, o edges, nel gergo dei grafi)? Succede che le GNN faticano ad aggregare tutte le informazioni utili, limitando le loro prestazioni. È come cercare di capire una città avendo solo metà della mappa stradale!
Ma non è finita qui. Le informazioni mancanti possono anche peggiorare un altro problema noto: l’overfitting. In pratica, il modello impara troppo bene i dati di addestramento, inclusi i suoi rumori e le sue peculiarità, e poi non riesce a generalizzare bene su dati nuovi e mai visti prima. È come uno studente che impara a memoria le risposte per un esame specifico, ma poi va in crisi se le domande cambiano leggermente. Questi due problemi – difficoltà nell’aggregare feature e rischio di overfitting – sono proprio quelli che PLGNN si propone di risolvere.
PLGNN alla Riscossa: Due Armi Segrete
E allora, come fa PLGNN a superare questi ostacoli? Semplice (si fa per dire!): introduce due strategie innovative che lavorano in sinergia.
1. Link Autostradali (High-way Links – HLs): Creare Scorciatoie Intelligenti
La prima idea geniale di PLGNN è quella di arricchire il grafo originale con dei “link autostradali”. Immaginate di dover raggiungere un punto lontano della città. Potreste fare un sacco di stradine secondarie, oppure potreste prendere un’autostrada diretta. Gli HLs funzionano un po’ così. Invece di affidarsi solo ai vicini diretti (1-hop), PLGNN va a cercare vicini di ordine superiore (amici di amici, amici di amici di amici, e così via) che appartengono però alla stessa classe del nodo di partenza. Se trova questi “parenti lontani ma affini”, crea un collegamento diretto, un vero e proprio link autostradale.
Perché è così utile? Perché permette al modello di aggregare feature da nodi più distanti in modo più efficiente. Se due nodi, anche se non direttamente connessi, condividono la stessa etichetta di classe, è probabile che abbiano caratteristiche rilevanti l’uno per l’altro. Questi HLs rendono il grafo più denso e ricco di informazioni, permettendo alle GNN di “vedere” più lontano e imparare rappresentazioni più accurate. Pensate, ad esempio, a una rete social: l’influenza di una persona non è data solo dagli amici diretti, ma anche dagli amici degli amici, specialmente se condividono interessi (la “classe”).

Gli esperimenti mostrano che l’uso di HLs basati sulla stessa classe è molto più efficace rispetto alla creazione di link generici con vicini di ordine superiore senza considerare la classe. Questi ultimi, infatti, potrebbero introdurre rumore e confondere il modello.
2. Perturbazione Adattiva delle Feature (Adaptive Feature Perturbation – AFP): Allenarsi nella Tempesta
La seconda arma di PLGNN è la perturbazione adattiva delle feature. L’idea qui è di rendere il modello più robusto e meno prono all’overfitting “disturbando” intelligentemente le feature dei nodi durante l’addestramento. Come funziona?
- Si inizia aggiungendo un po’ di rumore (seguendo una distribuzione Gaussiana) alle feature reali dei nodi.
- Poi, queste feature “rumorose” vengono proiettate in uno spazio iperbolico. Perché proprio iperbolico? Perché gli spazi iperbolici hanno proprietà geometriche particolari (come una crescita esponenziale del volume) che li rendono più adatti a rappresentare dati complessi e gerarchici rispetto al classico spazio Euclideo. È come dare più “respiro” alle feature per esprimersi.
- Infine, queste feature perturbate e proiettate vengono processate da un Multi-Layer Perceptron (MLP) e usate per un addestramento adattivo. Il modello impara a riconoscere i pattern corretti nonostante il rumore, diventando più bravo a distinguere le informazioni utili da quelle spurie.
Questo processo aiuta la GNN ad adattarsi al problema del rumore causato dalle informazioni mancanti e a non fare eccessivo affidamento sulle feature esistenti, riducendo così il rischio di overfitting. È come un atleta che si allena in condizioni difficili per essere pronto a tutto durante la gara.
Come Funziona il Tutto Insieme? Il Flusso di PLGNN
PLGNN integra queste due strategie in un framework ben preciso.
- Graph Data Augmentation (GraphDA) con HLs: Il grafo originale viene arricchito con i link autostradali, creando una nuova matrice di adiacenza “aumentata”. Questa matrice diventa l’input per il discriminatore.
- Adaptive Feature Perturbation (AFP): Le feature originali vengono perturbate, proiettate nello spazio iperbolico e processate per generare feature “disturbate”.
- Discriminatore (basato su GCN): Un discriminatore, che in questo caso è una Graph Convolutional Network (GCN), viene addestrato per compiti di classificazione (ad esempio, classificare i nodi o interi grafi). Riceve in input sia il grafo aumentato con HLs e le feature originali, sia le feature perturbate generate dall’AFP.
- Ottimizzazione: Il sistema viene ottimizzato attraverso due funzioni di perdita. Una per l’AFP, che mira a migliorare la capacità del modello di identificare le vere categorie nonostante le perturbazioni, e una per il discriminatore, che cerca di distinguere correttamente tra feature reali e perturbate, migliorando la classificazione finale.
L’interazione tra il discriminatore e il modulo AFP è iterativa: ad ogni epoca di addestramento, prima si affina il discriminatore, poi si raffinano le feature tramite AFP. Questo ciclo continuo porta a un modello sempre più robusto e performante.

PLGNN alla Prova dei Fatti: Risultati Sorprendenti
Basta teoria, parliamo di risultati! I ricercatori hanno messo alla prova PLGNN su ben dieci dataset del mondo reale: cinque per la classificazione dei nodi (come Cora, Citeseer, Pubmed) e cinque per la classificazione di interi grafi (come MUTAG, PROTEINS). Ebbene, PLGNN ha dimostrato una superiorità notevole rispetto ai metodi allo stato dell’arte.
In media, l’accuratezza è migliorata del 2.6% sui dataset di classificazione dei nodi e del 2.1% su quelli di classificazione dei grafi. Può sembrare poco, ma nel campo del machine learning, anche piccoli incrementi percentuali possono fare una grande differenza, specialmente quando si superano i metodi esistenti più avanzati! Addirittura, su alcuni dataset come Pubmed, PLGNN ha mostrato un incremento di accuratezza anche in presenza di un 30% di archi rimossi casualmente, mentre altri metodi peggioravano.
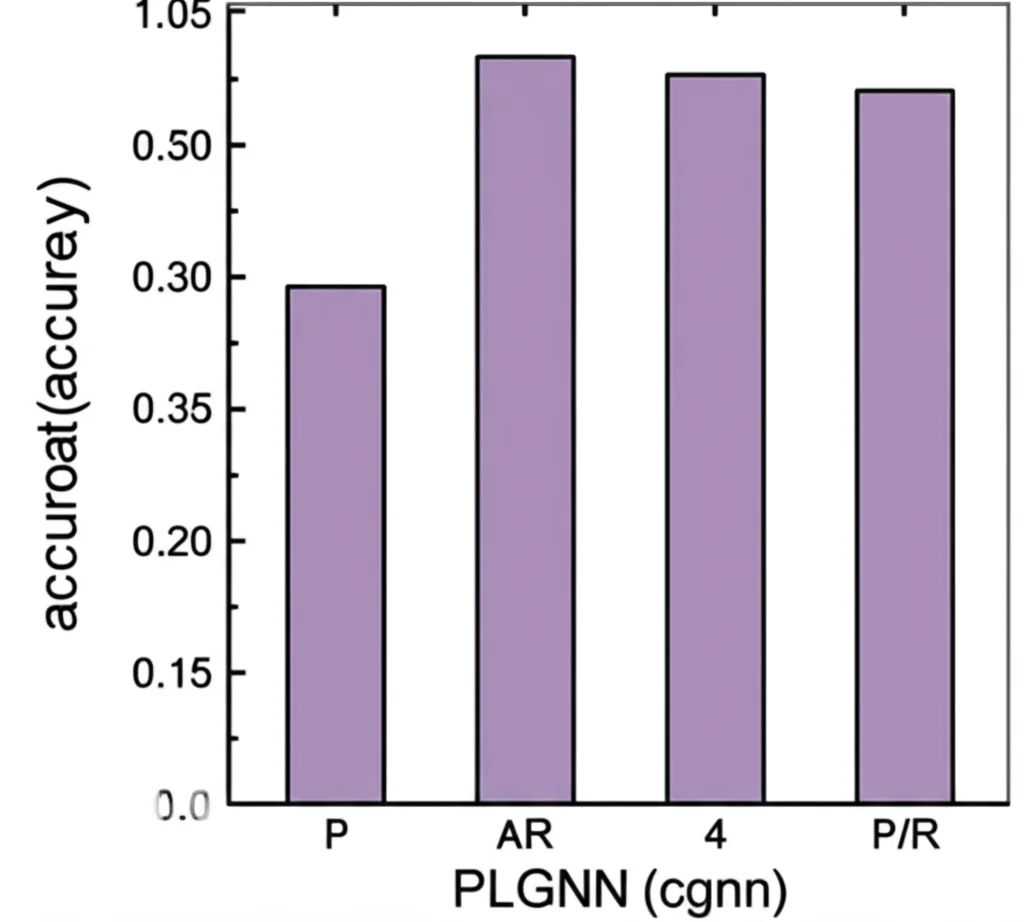
Gli studi di ablazione (cioè, esperimenti in cui si rimuovono componenti del modello per vederne l’impatto) hanno confermato che sia i link autostradali sia la perturbazione adattiva delle feature contribuiscono significativamente alle prestazioni. In particolare, la rimozione degli HLs ha causato il calo di performance più drastico, sottolineando l’importanza di questa strategia di aumento del grafo.
Un altro aspetto interessante è l’effetto dell’ordine degli HLs. Generalmente, considerare HLs di ordine superiore (fino al 4° ordine negli esperimenti, e sovrapponendoli, cioè includendo anche quelli di ordine inferiore) porta a risultati migliori, anche se l’effetto può variare leggermente a seconda del dataset specifico. Questo suggerisce che la capacità di “vedere” più lontano nella rete, in modo mirato, è davvero benefica.
Perché PLGNN è Speciale e Dove Potrebbe Portarci
Quindi, cosa rende PLGNN così speciale? A mio avviso, è la combinazione intelligente di due concetti potenti:
- HLs: Non si limita ad aggiungere archi a caso, ma lo fa in modo “consapevole”, cercando connessioni significative tra nodi della stessa classe a diversi ordini di distanza. Questo arricchisce la struttura del grafo in modo mirato.
- AFP con Proiezione Iperbolica: L’idea di perturbare le feature per migliorare la robustezza non è nuovissima, ma l’uso dello spazio iperbolico per gestire queste feature perturbate è una finezza che sfrutta geometrie non Euclidee per una migliore capacità rappresentativa.
Insieme, queste tecniche permettono a PLGNN di affrontare con più efficacia le informazioni mancanti e il rischio di overfitting, due dei talloni d’Achille delle GNN tradizionali. La robustezza e l’adattabilità di PLGNN lo rendono particolarmente promettente per applicazioni pratiche. Pensiamo al rilevamento di frodi nelle reti finanziarie, dove i dati sono spesso incompleti e i pattern sottili. O ai sistemi di raccomandazione, dove la sparsità dei dati è un problema comune. Anche nelle reti biologiche, come le interazioni proteina-proteina, dove i dati possono essere incerti, PLGNN potrebbe offrire insight più profondi.
Spero che questo viaggio nel mondo di PLGNN vi abbia incuriosito. È un esempio lampante di come la ricerca nell’intelligenza artificiale stia continuamente evolvendo, trovando soluzioni creative a problemi complessi. Chissà quali altre innovazioni ci aspettano dietro l’angolo nel fantastico universo delle reti neurali per grafi!
Fonte: Springer





