Acqua Più Chiara con l’IA: Il Mio Modello Ensemble Rivoluziona il Monitoraggio
Ciao a tutti! Oggi voglio parlarvi di qualcosa che mi sta davvero a cuore e su cui ho lavorato intensamente: la qualità dell’acqua. Sappiamo tutti quanto sia fondamentale per la vita sul nostro pianeta, per gli ecosistemi e per noi stessi. Monitorarla è cruciale, ma, diciamocelo, non è sempre stato facile farlo in modo affidabile.
Per anni ci siamo affidati ai cosiddetti modelli WQI (Water Quality Index), degli algoritmi matematici che cercano di condensare un sacco di parametri chimico-fisici in un unico numero, una sorta di “voto” alla salute dell’acqua. Utile, certo, ma questi modelli hanno ricevuto parecchie critiche. Perché? Principalmente per due grossi problemi che ho cercato di affrontare: l’eclissamento (eclipsing) e l’ambiguità (ambiguity).
Il Groviglio dell’Eclissamento e dell’Ambiguità
Vi spiego meglio. L’eclissamento è quando il valore finale del WQI sovrastima o sottostima la reale qualità dell’acqua. Magari un singolo parametro sballato “eclissa” tutti gli altri, dando un quadro distorto. Immaginate di giudicare un’intera orchestra basandovi solo sul suono troppo forte di un violino stonato! Questo può succedere per valori anomali o per come vengono “pesati” i diversi parametri nel calcolo. Un bel problema, perché ci porta a conclusioni sbagliate.
L’ambiguità, invece, si verifica quando diversi modelli WQI, applicati agli stessi dati, danno classificazioni diverse. Uno dice “acqua buona”, l’altro “scarsa”. E allora, di chi ci fidiamo? Questa incertezza rende difficile prendere decisioni informate sulla gestione delle risorse idriche.
Aggiungiamoci che i metodi tradizionali di monitoraggio sono spesso costosi, richiedono tempo, laboratori specializzati, personale qualificato e generano montagne di dati difficili da interpretare. Insomma, c’era bisogno di una svolta.
L’Intelligenza Artificiale Entra in Gioco
Ed è qui che entra in scena il mio campo d’azione preferito: l’intelligenza artificiale, in particolare il machine learning (ML). Negli ultimi anni, abbiamo visto tentativi promettenti di usare l’ML per migliorare i modelli WQI. L’idea è usare algoritmi che “imparano” dai dati storici per fare previsioni più accurate.
Sono stati usati diversi approcci: algoritmi per selezionare i parametri più rilevanti (come SVM, Random Forest, XGBoost), per assegnare pesi più oggettivi ai parametri, e naturalmente per predire direttamente il WQI o la sua classe (buona, discreta, scarsa, ecc.). Questi modelli basati su ML hanno mostrato miglioramenti rispetto a quelli convenzionali. Tuttavia, anche qui non sono mancate le sfide: a volte i risultati erano inconsistenti, specie a causa della variabilità intrinseca dei dati sulla qualità dell’acqua e della presenza di valori anomali (outliers).

La Mia Soluzione: Un Modello Ensemble Ottimizzato
Di fronte a queste sfide, mi sono chiesto: come possiamo creare un modello ML che sia davvero robusto e affidabile, minimizzando proprio quei fastidiosi problemi di eclissamento e ambiguità e gestendo meglio la variabilità dei dati? La risposta a cui sono arrivato è un modello ensemble ML-WQI ottimizzato.
Cosa significa “ensemble”? In pratica, invece di affidarsi a un singolo algoritmo ML, ne ho combinati diversi, sfruttando i punti di forza di ciascuno. Ho usato una tecnica chiamata stacking. Immaginatela come un team di esperti: ognuno dà il suo parere (la previsione), e poi c’è un “capo” (il meta-learner) che ascolta tutti e prende la decisione finale, quella più ponderata.
Per costruire questo “super modello”, ho fatto così:
- Ho selezionato otto noti modelli di regressione ML come candidati.
- Ho usato un dataset enorme e dettagliato: 29.159 campioni di qualità dell’acqua (fiumi e coste) raccolti in 15 anni (2007-2023) dall’Agenzia per la Protezione Ambientale Irlandese (EPA). Ogni campione aveva 11 parametri misurati.
- Ho pre-processato i dati con cura: gestione dei valori mancanti (usando la mediana, adatta per dati mancanti casualmente come i nostri), e rimozione degli outlier tramite normalizzazione z-score.
- Ho calcolato i WQI per ogni campione usando tre modelli tradizionali noti: CCME, Brown e SRDD. Questi WQI “tradizionali” mi sono serviti come riferimento per addestrare i miei modelli base.
- Ho addestrato i candidati ML per vedere quali “imitavano” meglio le classificazioni dei tre modelli tradizionali.
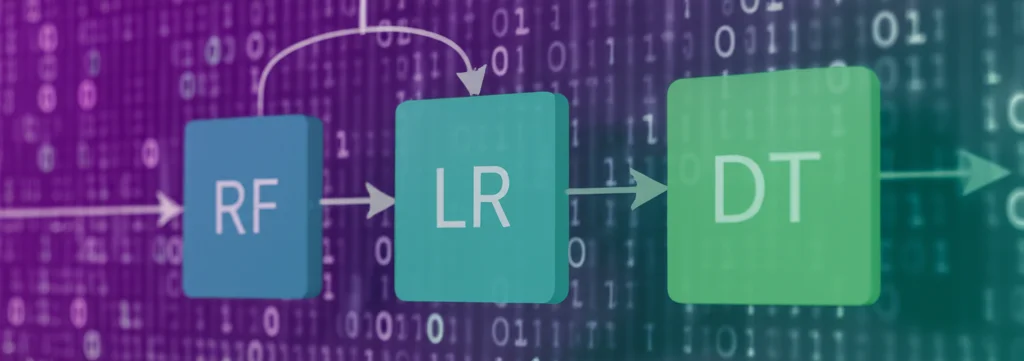
- Alla fine, ho scelto i tre migliori come stimatori di base (base-estimators): Random Forest (RF) per “replicare” il CCME, Linear Regression (LR) per il Brown, e Extreme Gradient Boosting (XGB) per l’SRDD.
- Le previsioni di questi tre modelli base sono state poi date in pasto a un meta-apprenditore (meta-learner). Dopo aver testato cinque candidati, il migliore è risultato essere il Decision Tree (DT).
Quindi, il mio modello ensemble finale funziona così: RF, LR e XGB fanno una prima stima del WQI basandosi sui dati grezzi, e poi DT combina queste stime per dare la previsione finale, più accurata e robusta.
Risultati Sorprendenti: Accuratezza e Resilienza
E i risultati? Beh, sono stati davvero entusiasmanti! Per valutare le performance ho usato metriche standard come l’Errore Quadratico Medio (MSE), l’Errore Assoluto Medio (MAE), la Radice dell’Errore Quadratico Medio (RMSE) e il coefficiente R-quadro (R²), oltre alla convalida incrociata a cinque fold (fivefold cross-validation) per assicurarmi che il modello non fosse “imparato a memoria” solo i dati di training (overfitting).
Il mio modello ensemble ha raggiunto punteggi incredibili:
- MAE: 0.01
- MSE: 0.001
- RMSE: 0.0034
- R²: 1.00 (praticamente perfetto!)
Questi valori, vicinissimi allo zero per gli errori e a 1 per R², indicano un’accuratezza predittiva elevatissima e una grande sensibilità del modello. La convalida incrociata ha confermato la sua robustezza (RMSE basso, 0.017). Confrontando questi risultati con altri modelli ML-WQI presenti in letteratura, il mio approccio ensemble si è dimostrato nettamente superiore.
Ma la cosa forse più importante è stata la valutazione della resilienza ai problemi di eclissamento e ambiguità.
Addio (o Quasi) a Eclissamento e Ambiguità
Per testare l’eclissamento, ho creato delle versioni “disturbate” del dataset, introducendo apposta valori fuori range per uno o due parametri, simulando così situazioni critiche. Ebbene, mentre i modelli tradizionali mostravano tassi di eclissamento (soprattutto sottostima) molto alti (dal 32% al 77% con un parametro fuori range, e fino al 99% con due!), il mio modello ensemble ha mantenuto un tasso bassissimo (23.9% con un parametro fuori range, salito solo al 28% con due). Inoltre, le sue previsioni, anche in presenza di dati anomali, rimanevano molto più vicine alla tendenza reale della qualità dell’acqua, senza quegli “sbalzi” estremi visti negli altri modelli, specialmente l’SRDD. Fondamentalmente, il modello ensemble è molto più stabile.
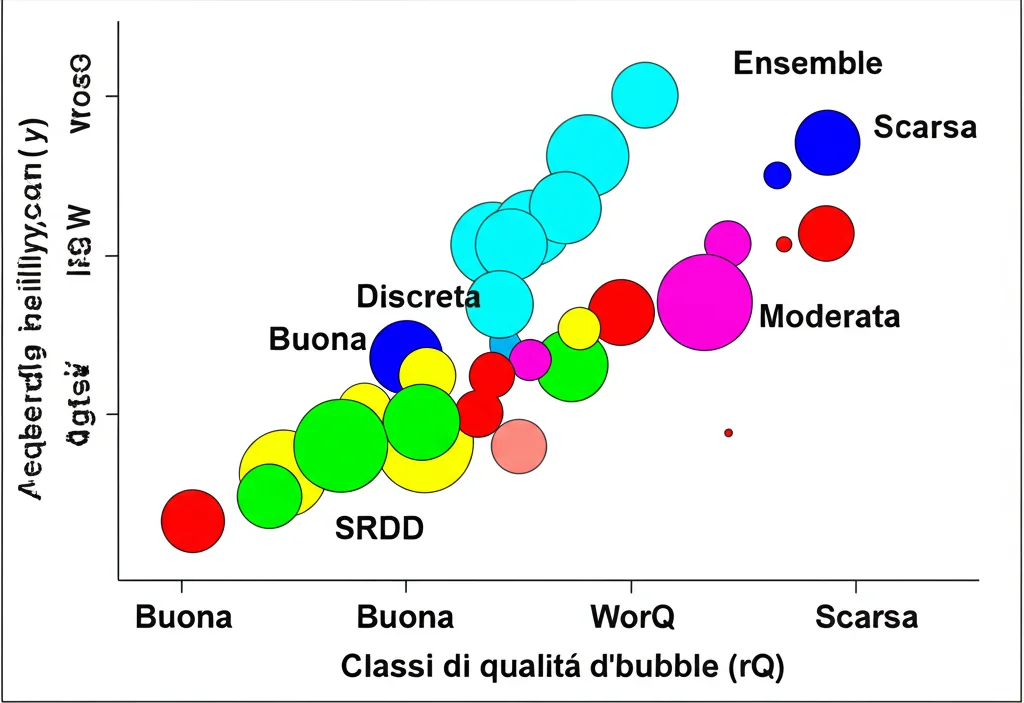
Per l’ambiguità, ho analizzato i casi in cui i diversi modelli davano classificazioni discordanti per gli stessi dati. Usando visualizzazioni come scatter plot e bubble plot, è emerso chiaramente che il modello SRDD produceva spesso classificazioni molto diverse (spesso peggiori) rispetto agli altri tre (CCME, Brown e il mio ensemble). Il mio modello, invece, mostrava una grande coerenza con CCME e Brown, classificando il 99% dei campioni come “Buona” o “Discreta”, in linea con la qualità attesa delle acque irlandesi studiate, e senza mai classificare come “Scarsa”. Questo dimostra una maggiore stabilità e affidabilità, riducendo l’incertezza interpretativa.
Perché Funziona Così Bene?
Credo che il successo di questo modello derivi dalla sua architettura “a due livelli”. Gli stimatori di base (RF, LR, XGB) fanno un “apprendimento cognitivo”, catturando pattern e variabilità dai dati storici e imitando i comportamenti dei modelli tradizionali. Il meta-apprenditore (DT) fa un “apprendimento strategico”, migliorando il processo decisionale analizzando le previsioni dei modelli base. Questa combinazione permette al modello di “riflettere” sulla tendenza dei dati e di essere più resiliente agli inevitabili “rumori” e alle incertezze.
Implicazioni Reali e Prospettive Future
Questo modello ensemble ML-WQI non è solo un esercizio accademico. Ha il potenziale per cambiare davvero le cose. Essendo data-driven, autonomo, cost-effective e relativamente facile da interpretare, può supportare concretamente la creazione di sistemi di monitoraggio e gestione della qualità dell’acqua più efficienti, tempestivi e completi. Immaginate sistemi che ci avvisano in tempo reale di potenziali problemi, riducendo la necessità di analisi di laboratorio lunghe e costose e l’intervento umano costante.
Certo, ci sono delle limitazioni. L’addestramento di un modello ensemble richiede più tempo e risorse computazionali rispetto a un modello singolo, e necessita di grandi quantità di dati etichettati, che non sempre sono disponibili.
Ma le prospettive sono entusiasmanti. Il prossimo passo sarà testare il modello su dataset diversi, per migliorarne ulteriormente la generalizzabilità. Si potrebbero includere più parametri, integrare dati in tempo reale, esplorare modelli di deep learning ancora più avanzati, considerare le variazioni stagionali e ottimizzare i tempi di addestramento.
In conclusione, credo fermamente che questo approccio ensemble rappresenti un passo avanti significativo verso una previsione della qualità dell’acqua più affidabile e accurata. È uno strumento potente che può aiutarci a proteggere meglio una delle nostre risorse più preziose. E per me, contribuire a questo obiettivo è una soddisfazione enorme!

Fonte: Springer