
Smart Contract Sicuri? Il Nostro Metodo Leggero Scova le Falle (Anche le Più Nascoste!)
Ciao a tutti! Oggi voglio parlarvi di qualcosa che mi appassiona tantissimo e che sta rivoluzionando molti settori, dalla finanza alla sanità: gli smart contract sulla blockchain, in particolare su Ethereum. Immaginate contratti che si eseguono da soli, in modo trasparente e senza bisogno di intermediari. Fantastico, vero? Permettono transazioni sicure, efficienti e a basso costo.
Però, come in tutte le cose belle, c’è un “ma”. Questi contratti, una volta pubblicati sulla blockchain, sono immutabili. Se contengono errori o, peggio, vulnerabilità, possono diventare un bersaglio facile per malintenzionati. E le conseguenze possono essere disastrose! Ricordate l’attacco a The DAO nel 2017? 50 milioni di dollari persi a causa di una vulnerabilità di tipo “Reentrancy”. O i problemi del wallet Parity, costati oltre 180 milioni. Capite bene che trovare queste falle *prima* che il contratto venga reso pubblico è fondamentale.
Il problema: Scovare le vulnerabilità, soprattutto nei contratti lunghi
Negli anni sono nati tanti metodi per scovare queste vulnerabilità. Ci sono quelli “tradizionali”, come l’analisi statica (Taint analysis, Symbolic execution), il fuzz testing o la verifica formale. Funzionano, certo, ma hanno i loro limiti: spesso si basano su regole predefinite e faticano a identificare vulnerabilità nuove o complesse. Inoltre, analizzare contratti molto grandi può portare a un’esplosione di percorsi da controllare, rendendo il processo lento e inefficiente.
Poi è arrivato il deep learning. L’idea è geniale: addestrare un modello con tantissimi esempi di contratti vulnerabili e non, insegnandogli a riconoscere i pattern pericolosi. Molti metodi attuali usano reti neurali come LSTM (Long Short-Term Memory) o sue varianti. Funzionano bene per contratti brevi o di media lunghezza. Ma quando il gioco si fa duro, e i contratti diventano lunghi centinaia o migliaia di righe di codice, queste reti iniziano a perdere colpi. Faticano a “ricordare” dipendenze tra parti di codice molto distanti tra loro, proprio dove spesso si nascondono le vulnerabilità più subdole.
Certo, ci sarebbero i Large Language Models (LLM), i “cervelloni” alla base di ChatGPT, che sono bravissimi con testi lunghi. Ma richiedono una potenza di calcolo enorme, sia per l’addestramento che per l’uso. Non proprio alla portata di tutti gli sviluppatori che magari lavorano su un normale PC d’ufficio.
Un altro problema è che molti metodi si concentrano su una sola “modalità” del contratto, ad esempio solo il codice sorgente (quello scritto in Solidity) o solo l’opcode (le istruzioni a basso livello eseguite dalla Ethereum Virtual Machine – EVM). Ma perché limitarsi? Entrambi contengono informazioni preziose e complementari!

La nostra soluzione: Leggerezza, Bimodalità e Attenzione Gerarchica
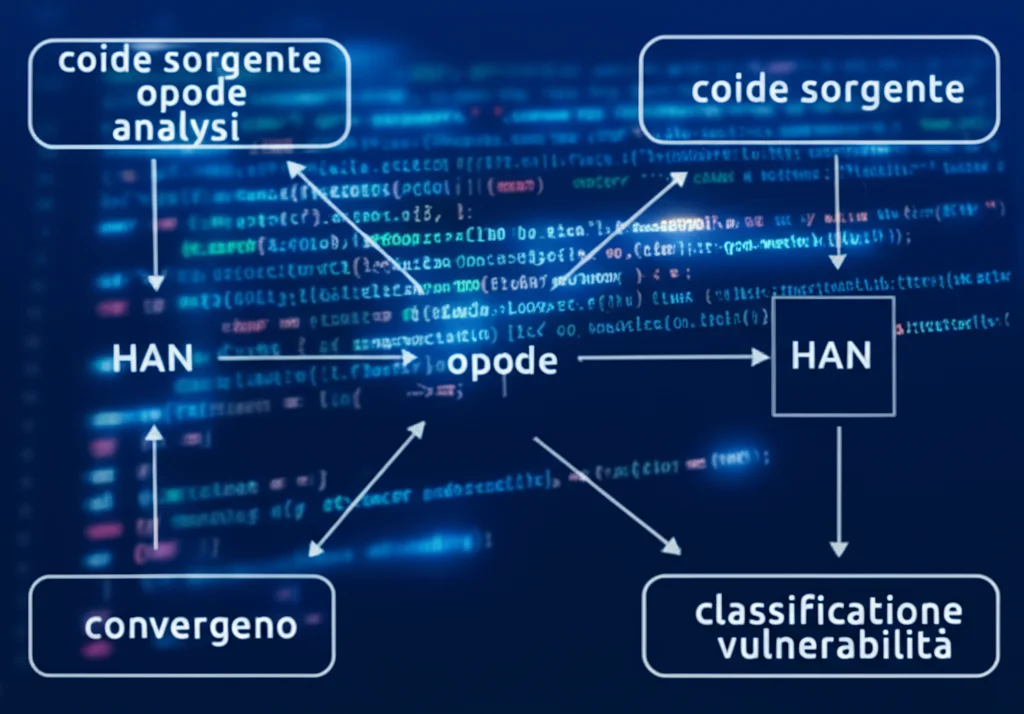
Ed è qui che entra in gioco la nostra idea! Abbiamo sviluppato un metodo leggero per la rilevazione di vulnerabilità, pensato specificamente per i contratti lunghi, che sfrutta la potenza dell’analisi bimodale e di una rete neurale chiamata Hierarchical Attention Network (HAN).
Cosa significa “bimodale”? Semplicemente che analizziamo *sia* il codice sorgente *sia* l’opcode del contratto. È come avere due detective che esaminano la scena del crimine da due prospettive diverse: uno guarda i dettagli generali (il codice sorgente), l’altro le impronte digitali e le tracce microscopiche (l’opcode). Mettendo insieme le loro scoperte, otteniamo un quadro molto più completo e accurato.
E la rete HAN? È la nostra arma segreta per i contratti lunghi. A differenza delle LSTM tradizionali, la HAN è strutturata gerarchicamente. Prima analizza le singole “frasi” (porzioni di codice), dando più “attenzione” alle parole chiave importanti al loro interno. Poi, combina queste frasi, dando più peso a quelle che sembrano più rilevanti per identificare una vulnerabilità. Questo approccio le permette di catturare dipendenze a lungo raggio senza richiedere le risorse esorbitanti di un LLM. È potente, ma rimane leggera!
Come funziona il nostro metodo, passo dopo passo
Vediamo un po’ più nel dettaglio come opera il nostro sistema:
- Input dei Dati: Diamo in pasto al sistema sia il codice sorgente (scritto in Solidity) che l’opcode corrispondente (ottenuto compilando il sorgente).
- Pulizia e Preparazione (Preprocessing): Questa è una fase cruciale. “Puliamo” sia il codice sorgente che l’opcode. Togliamo commenti, nomi di variabili non standard, istruzioni inutili o ridondanti. Standardizziamo il formato. L’obiettivo è ridurre il “rumore” e lasciare solo le informazioni essenziali per l’analisi delle vulnerabilità. Abbiamo visto che questo passaggio da solo migliora già l’accuratezza!
- Trasformare le Parole in Vettori (Word Embedding): Le reti neurali non capiscono le parole, ma i numeri. Usiamo una tecnica chiamata FastText (che nei nostri test si è rivelata migliore di Word2vec per questo compito) per trasformare ogni “parola” (sia nel sorgente che nell’opcode) in un vettore numerico che ne cattura il significato semantico. FastText è bravo anche con parole rare, cosa utile perché a volte le vulnerabilità dipendono da termini poco comuni.
- Il Cuore del Sistema: Analisi con HAN: Ora entrano in gioco due reti HAN parallele, una per il sorgente vettorizzato e una per l’opcode vettorizzato. Ciascuna rete, come dicevo, lavora su due livelli: prima a livello di parola (trovando le parole più importanti in ogni segmento di codice) e poi a livello di frase/segmento (trovando i segmenti più indicativi di una possibile vulnerabilità).
- Unire le Forze (Feature Fusion): I risultati delle due analisi (sorgente e opcode) vengono poi fusi insieme. In questo modo, il modello ottiene una visione d’insieme, combinando le informazioni di alto livello del sorgente con quelle di basso livello dell’opcode.
- Il Verdetto Finale (Output): L’output finale viene processato da uno strato Softmax che classifica il contratto, indicando se è vulnerabile a uno dei tipi di attacco che abbiamo considerato (nel nostro studio ci siamo concentrati su quattro tipi molto comuni e dannosi: Denial of Service, Reentrancy, Arithmetic – overflow/underflow – e Timestamp Dependency) o se è pulito.
I tipi di vulnerabilità che scoviamo
Giusto per darvi un’idea più concreta, ecco brevemente cosa sono le quattro vulnerabilità su cui ci siamo concentrati:
- Denial of Service (DoS): Un attaccante sfrutta una falla per impedire ad altri utenti di usare il contratto o per consumare tutte le risorse (gas), bloccandone il funzionamento.
- Reentrancy: L’attaccante riesce a richiamare ripetutamente una funzione del contratto (spesso quella di prelievo fondi) prima che la chiamata iniziale sia terminata, prosciugando le risorse. È la vulnerabilità che ha colpito The DAO.
- Arithmetic (Overflow/Underflow): Errori nei calcoli con numeri interi. Ad esempio, se un valore supera il massimo consentito (overflow) o scende sotto lo zero (underflow) in modo imprevisto, può portare a comportamenti anomali e perdite di fondi.
- Timestamp Dependency: Il contratto basa la sua logica sull’orario (timestamp) del blocco. I miner (che decidono il timestamp) potrebbero manipolarlo a proprio vantaggio.
Queste sono solo quattro, ma il nostro approccio basato sul deep learning è flessibile e potrebbe essere addestrato per riconoscere anche altri tipi di vulnerabilità.
Alla prova dei fatti: I risultati sperimentali
Ovviamente, non ci siamo fermati alla teoria. Abbiamo messo alla prova il nostro metodo su un dataset pubblico bello corposo (Smartbug-wild), contenente migliaia di smart contract reali. Abbiamo filtrato e verificato manualmente i contratti per creare un set di dati affidabile per le quattro vulnerabilità target.
I risultati sono stati davvero incoraggianti! Abbiamo confrontato il nostro metodo (chiamiamolo Bimodal-HAN) con:
- Versioni “monomodali” che usano solo il sorgente (Sourcecode-HAN) o solo l’opcode (Opcode-HAN).
- Altri metodi di deep learning all’avanguardia proposti da altri ricercatori (basati su BiLSTM, CNN, Attention, TripletLoss, ecc.).
Cosa abbiamo scoperto?
1. Bimodale è meglio: Il nostro Bimodal-HAN ha ottenuto un’accuratezza significativamente maggiore rispetto alle versioni che usano solo sorgente o solo opcode. Analizzare entrambe le modalità paga! L’accuratezza generale ha raggiunto l’89.089%, superando di quasi il 3% l’analisi del solo sorgente.
2. Superiorità sui contratti lunghi: Qui il nostro metodo ha brillato davvero. Abbiamo diviso il set di test in contratti “corti” (sorgente < 700 caratteri/token) e "lunghi". Sui contratti lunghi, il nostro Bimodal-HAN ha raggiunto un'accuratezza dell'82.977%, superando il miglior metodo concorrente di oltre il 9%! E rispetto ad altri metodi basati su LSTM/CNN, il vantaggio era ancora più marcato (dall’11% al 13% in più). Questo conferma che la rete HAN è molto più efficace nel gestire le dipendenze a lungo raggio.

3. Buone performance anche sui corti: Anche sui contratti più corti, il nostro metodo si è comportato molto bene, superando tutti gli altri, anche se con un margine minore (circa 1.6% sul secondo migliore). Questo suggerisce che l’informazione aggiuntiva dell’opcode aiuta anche quando la lunghezza non è il problema principale.
4. Efficacia su tutte le vulnerabilità: Il nostro metodo ha mostrato ottime performance (precision, recall, F1-score) su tutte e quattro le vulnerabilità analizzate, superando gli altri metodi in quasi tutte le metriche, specialmente sui contratti lunghi.
5. Velocità vs Accuratezza: C’è un piccolo compromesso. Essendo bimodale, il nostro metodo analizza più dati per ogni contratto, quindi è leggermente più lento rispetto ai metodi monomodali (parliamo comunque di frazioni di secondo per contratto, quindi rimane assolutamente “leggero” e utilizzabile su hardware comune). Ma l’enorme guadagno in accuratezza, soprattutto sui contratti complessi, a nostro avviso vale decisamente la pena.
Abbiamo anche sperimentato con diversi parametri, come la lunghezza dei “segmenti” in cui la rete HAN divide il codice. Abbiamo scoperto che una lunghezza tra 70 e 120 caratteri/token dà i risultati migliori, trovando il giusto equilibrio tra catturare abbastanza contesto e non rendere i segmenti troppo lunghi per l’analisi interna della HAN.
Limiti e Prospettive Future
Siamo molto soddisfatti dei risultati, ma siamo anche consapevoli dei limiti. Come accennato, c’è il trade-off velocità/accuratezza. Inoltre, sebbene la HAN sia ottima per i testi lunghi, il suo meccanismo di segmentazione potrebbe, in teoria, “spezzare” una caratteristica di vulnerabilità che si trova a cavallo tra due segmenti, specialmente in contratti molto corti. Anche se i risultati sui contratti corti sono comunque eccellenti, è un aspetto che vogliamo indagare ulteriormente.
Per il futuro, vogliamo continuare a migliorare il modello. Stiamo pensando a come mitigare ulteriormente l’impatto della segmentazione sui contratti più corti e magari esplorare tecniche di fusione delle feature ancora più sofisticate. L’obiettivo è rendere il rilevamento delle vulnerabilità ancora più preciso ed efficiente.

In conclusione
La sicurezza degli smart contract è una sfida cruciale per il futuro della blockchain. Con il nostro metodo bimodale basato su HAN, crediamo di aver fatto un passo avanti importante, offrendo uno strumento leggero, accessibile, ma estremamente efficace nel scovare vulnerabilità, specialmente in quei contratti lunghi e complessi dove i metodi tradizionali faticano di più.
È uno strumento che gli sviluppatori possono usare facilmente sui loro computer per rendere i loro smart contract più sicuri prima del rilascio, contribuendo a costruire un ecosistema blockchain più affidabile per tutti. E noi non vediamo l’ora di continuare a migliorarlo!
Fonte: Springer





