
Rifiuti che Valgono Oro: L’Intelligenza Artificiale Svela il Loro Potere Energetico!
Ciao a tutti! Oggi voglio parlarvi di qualcosa che ci riguarda da vicino: i nostri rifiuti. Sì, proprio quella montagna di cose che buttiamo via ogni giorno. Sapete che la produzione globale di rifiuti è aumentata a dismisura? E questo, diciamocelo, crea un bel po’ di problemi per il nostro pianeta: inquinamento, rischi per la salute, spreco di risorse preziose. È urgente trovare modi intelligenti per gestire questa situazione, vero?
Perché i Rifiuti Sono un Problema (e un’Opportunità)
Una gestione dei rifiuti fatta male è un disastro ambientale. Ma se fatta bene, può trasformare un problema in una risorsa. Pensateci: meno rifiuti in discarica, più materiali riciclati e, udite udite, la possibilità di produrre energia! Sì, perché i nostri rifiuti urbani solidi (quelli che tecnicamente chiamiamo RSU o MSW, dall’inglese Municipal Solid Waste) contengono energia. Possiamo “catturarla” usando tecnologie come la combustione, la pirolisi o la gassificazione. Immaginate di poter ridurre la nostra dipendenza dai combustibili fossili semplicemente… gestendo meglio la spazzatura! Sarebbe un passo enorme verso un futuro più sostenibile e un’economia circolare, dove nulla (o quasi) si butta davvero.
Il Cuore Energetico dei Rifiuti: Il Potere Calorifico
Ma quanta energia c’è davvero nei rifiuti? La risposta sta nel loro potere calorifico (HV – Heating Value). Conoscere questo valore è fondamentale per progettare e far funzionare bene gli impianti che trasformano i rifiuti in energia (i cosiddetti termovalorizzatori). Il problema è che misurare questo potere calorifico non è affatto semplice. Di solito si usa uno strumento chiamato “bomba calorimetrica”, ma ha i suoi limiti. Primo, si usa un campione piccolissimo (tipo 1 grammo) per rappresentare tonnellate di rifiuti super eterogenei. Secondo, non tutti gli impianti hanno questa attrezzatura costosa. Terzo, le misurazioni possono essere lunghe, costose e soggette a errori. Insomma, ci serviva un modo migliore.
Entra in Scena il Machine Learning!
Ed è qui che entriamo in gioco noi, con il nostro studio e la magia del machine learning (ML). L’intelligenza artificiale, e in particolare il ML, ci permette di analizzare montagne di dati per scovare schemi e relazioni nascoste. Nel nostro caso, ci siamo chiesti: possiamo usare il ML per predire il potere calorifico dei rifiuti basandoci sulle loro caratteristiche? La risposta, come vedrete, è un sonoro SÌ! Abbiamo preso i dati sulla composizione fisica dei rifiuti (quanta carta, plastica, organico, ecc.) e sulla loro analisi chimica elementare (quanto carbonio, idrogeno, ossigeno, azoto, zolfo e ceneri contengono) e li abbiamo dati “in pasto” a diversi algoritmi di ML.

I Nostri “Agenti Speciali”: XGBoost, Extra Trees, CatBoost e MLR
Per questa missione predittiva, abbiamo schierato alcuni dei migliori algoritmi di ML in circolazione:
- XGBoost (eXtreme Gradient Boosting): Un algoritmo super efficiente e veloce, famoso per la sua precisione. Costruisce progressivamente un team di “alberi decisionali” che imparano dagli errori precedenti.
- Extra Trees (Extremely Randomized Trees): Simile a XGBoost ma ancora più “random” nel costruire gli alberi, il che lo rende ottimo per evitare di “imparare a memoria” i dati (overfitting).
- CatBoost: Un altro pezzo da novanta del gradient boosting, particolarmente bravo a gestire dati “categorici” (come i tipi di plastica, ad esempio) senza troppi passaggi preliminari.
- Multiple Linear Regression (MLR): Il nostro “metro di paragone” tradizionale. Cerca una relazione lineare semplice tra le caratteristiche dei rifiuti e il loro potere calorifico.
Abbiamo usato Python e la libreria scikit-learn (un classico per chi fa ML) per costruire e allenare questi modelli. I dati provenivano da 24 contee della provincia di Khorasan Razavi, in Iran, grazie alla collaborazione con l’organizzazione di gestione dei rifiuti solidi di Mashhad. Abbiamo raccolto dati sulla composizione fisica in primavera ed estate e poi abbiamo calcolato il potere calorifico usando una versione modificata della formula di Dulong, che tiene conto proprio degli elementi chimici (C, H, O, N, S).
Il Campione Indiscusso: Extra Trees
Dopo aver allenato e testato i nostri modelli (usando l’80% dei dati per l’allenamento e il 20% per il test, una pratica standard), abbiamo tirato le somme. Ebbene, il modello Extra Trees si è rivelato una vera superstar! Ha ottenuto un punteggio R² (che misura quanto bene il modello spiega la variabilità dei dati reali) di 0.999 nel training e un incredibile 0.979 nel testing. Questo significa che è stato bravissimo a imparare e ancora più bravo a generalizzare su dati mai visti prima! Anche gli errori di predizione (misurati con MSE, MAE e MAPE) erano bassissimi. Ad esempio, l’Errore Quadratico Medio (MSE) sul set di test era solo 77,455.92, molto più basso degli altri.
Anche XGBoost e CatBoost hanno fatto un ottimo lavoro, con R² alti, ma Extra Trees li ha battuti proprio sul filo di lana, soprattutto in termini di errori minimi. Il povero MLR, il metodo tradizionale, ha mostrato prestazioni solo moderate, confermando che per problemi complessi come questo, gli algoritmi più moderni hanno una marcia in più.
Cosa Conta Davvero per l’Energia dei Rifiuti?
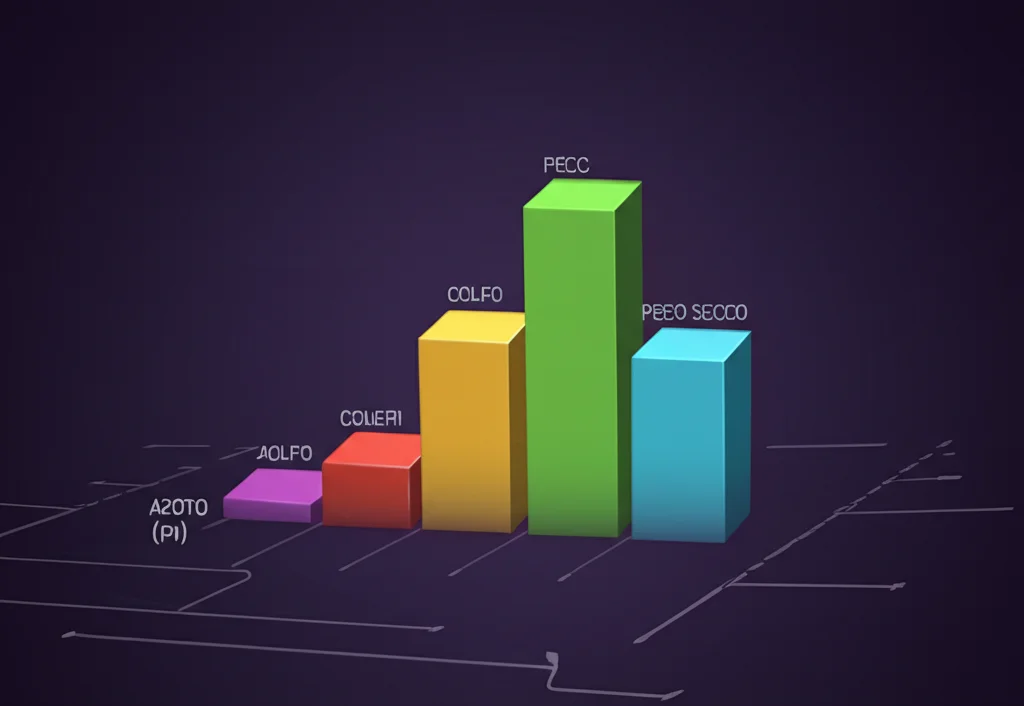
Una delle cose più affascinanti del ML è che può dirci quali fattori sono più importanti per le sue predizioni. Nel nostro modello Extra Trees, abbiamo scoperto che i “pesi massimi” nel determinare il potere calorifico erano:
- Contenuto di Azoto (N): Sorprendentemente, è risultato il fattore più influente (27.5% dell’importanza totale), ma con un impatto negativo. L’azoto non brucia e la sua presenza “diluisce” i componenti energetici.
- Contenuto di Zolfo (S): Secondo posto (26% di importanza), con un impatto positivo. Anche se non è una fonte primaria di energia, la sua presenza potrebbe essere legata ad altri materiali ad alto potere calorifico.
- Contenuto di Ceneri: Terzo posto. Le ceneri sono ciò che rimane dopo la combustione, quindi più ce ne sono, meno materiale combustibile c’era all’inizio (impatto negativo indiretto).
- Peso del Campione Secco: Quarto posto. Logico: più materiale combustibile (secco) c’è, più energia potenziale c’è.
Carbonio (C) e Idrogeno (H), che sono i veri “carburanti” nella combustione, insieme all’Ossigeno (O), contribuivano per il resto. È interessante notare come i nostri risultati differiscano leggermente da altri studi, probabilmente a causa delle diverse tipologie di rifiuti analizzate. Questo sottolinea quanto sia importante adattare i modelli alle condizioni locali. Abbiamo anche usato delle tecniche chiamate Partial Dependence Plots (PDPs) per visualizzare come ogni fattore influenza il potere calorifico, confermando queste relazioni (positive per C, H, O, S, peso secco, ceneri; negativa per N).
Verso una Gestione dei Rifiuti più Intelligente
Cosa significa tutto questo in pratica? Significa che abbiamo sviluppato uno strumento potentissimo basato sul machine learning, in particolare sul modello Extra Trees, che può predire con grande accuratezza il potenziale energetico dei rifiuti urbani semplicemente conoscendone la composizione fisica e chimica. Questo può aiutare enormemente chi gestisce gli impianti di trattamento e recupero energetico a:
- Ottimizzare i processi.
- Prendere decisioni più informate.
- Massimizzare il recupero di energia.
- Contribuire attivamente alla transizione verso un’economia circolare e un futuro più sostenibile.
Certo, il nostro studio si basa su dati di una specifica regione iraniana. La sfida ora è ampliare il dataset, includendo dati da più città e con caratteristiche dei rifiuti ancora più variegate, per rendere i modelli ancora più robusti e generalizzabili. Ma la strada è tracciata: l’intelligenza artificiale può davvero trasformare i nostri rifiuti da problema a preziosa risorsa energetica!
Fonte: Springer





