
Linguistica Computazionale: Viaggio al Cuore delle Parole e dei Computer (Analisi Scientometrica)
Ciao a tutti! Oggi voglio portarvi con me in un viaggio affascinante nel mondo della linguistica computazionale. Sembra un termine complesso, vero? Ma in realtà, è l’incredibile punto d’incontro tra il linguaggio umano, con tutte le sue sfumature, e la potenza dei computer. Pensateci: è un campo super interdisciplinare che mescola linguistica, informatica, intelligenza artificiale (IA) e scienze cognitive. In pratica, usiamo i computer per capire e processare il linguaggio, un po’ come cercare di insegnare a una macchina a “parlare” e “capire” come noi.
L’Associazione di Linguistica Computazionale (ACL), un punto di riferimento nel settore, la definisce come “lo studio scientifico del linguaggio da una prospettiva computazionale”, cercando di creare modelli che spieghino i fenomeni linguistici, sia basandosi su regole (knowledge-based) che sui dati (data-driven) con analisi statistiche.
Come tutto ebbe inizio: una storia affascinante
Vi siete mai chiesti come sia nata questa disciplina? Beh, la storia è davvero interessante e inizia quasi per necessità. Siamo negli anni ’40, durante la Seconda Guerra Mondiale. Il governo americano aveva un bisogno impellente: tradurre testi dal russo all’inglese. Ed ecco l’idea folle (per l’epoca): insegnare ai computer a tradurre! Certo, si rivelò molto più difficile del previsto, ma fu la scintilla che diede vita alla traduzione automatica e, di conseguenza, alla linguistica computazionale.
Un certo Warren Weaver, già nel 1949, parlava della possibilità della traduzione automatica. Poi arrivarono le prime conferenze (MIT, 1952) e la prima rivista dedicata (“Mechanical Translation”, 1954). Lo sviluppo storico può essere diviso in fasi:
- Anni ’40-’60: L’era pionieristica della traduzione automatica e la nascita del Natural Language Processing (NLP).
- Anni ’60-’70: L’Intelligenza Artificiale entra in gioco per potenziare l’NLP, con sistemi famosi come BASEBALL, SHRDLU e LUNAR.
- Anni ’70-’80: Il focus si sposta sulla grammatica e la semantica, integrando logica e teorie grammaticali computazionali per capire anche le intenzioni dell’utente.
- Anni ’90 ad oggi: L’approccio lessicale si rafforza, si usano metodi statistici e l’analisi si sposta su testi reali (come le notizie). Nascono grandi risorse linguistiche come il British National Corpus e WordNet.
È un percorso incredibile, guidato dalla necessità, dalla curiosità e dai progressi tecnologici!
L’impatto rivoluzionario dell’IA e del Machine Learning
Non possiamo parlare di linguistica computazionale oggi senza menzionare l’enorme impatto dell’intelligenza artificiale, del machine learning (ML) e del deep learning. Queste tecnologie hanno letteralmente trasformato il campo. Hanno permesso ai computer di interagire con noi in modi che sembrano quasi umani, superando barriere linguistiche (pensate all’importanza in contesti multilingue come l’Asia) e aprendo porte a nuove applicazioni.
Certo, sfide ne rimangono. Far capire a una macchina le metafore o la poesia come farebbe un umano è ancora un traguardo lontano. Ma i progressi sono stati enormi, spinti dalla potenza di calcolo crescente, dalla disponibilità di enormi quantità di dati linguistici (i cosiddetti *corpora*) e da un approccio sempre più basato sull’analisi statistica dei dati. Oggi, tecnologie nate dalla linguistica computazionale, come i motori di ricerca o i sistemi di riconoscimento vocale, sono parte della nostra vita quotidiana.

Di cosa si occupa chi fa linguistica computazionale?
Il bello di questo campo è la sua vastità. Si può avere una base informatica e applicarla alla linguistica, o viceversa. Le aree di ricerca sono tantissime, eccone alcune:
- Traduzione computazionale
- Fonetica e fonologia computazionale
- Morfologia computazionale (come si formano le parole)
- Lessicografia computazionale (creazione di dizionari)
- Sintassi computazionale (analisi della struttura delle frasi)
- Semantica computazionale (studio del significato)
- Pragmatica computazionale (linguaggio nel contesto)
- Analisi del discorso computazionale
- Acquisizione del linguaggio
- Corpus linguistics (analisi di grandi raccolte di testi)
- Natural Language Processing (NLP)
- Analisi della complessità del linguaggio
- Segmentazione del testo
- Gestione dell’ambiguità linguistica
- Part-of-speech tagging (etichettare le parti del discorso)
- Riconoscimento e generazione del linguaggio
- Machine learning e Deep learning applicati al linguaggio
- Sentiment analysis (capire le opinioni nei testi)
- Text and data mining
E la lista potrebbe continuare! Si lavora su tante lingue, anche se l’inglese è stato storicamente il più studiato.
La comunità scientifica e le sue risorse
Un campo così dinamico ha bisogno di una comunità forte. L’Association for Computational Linguistics (ACL), nata nel 1962 (inizialmente come AMTCL), è il punto di riferimento mondiale. Organizza conferenze annuali e sponsorizza riviste fondamentali come “Computational Linguistics” (pubblicata da MIT Press, attiva da decenni) e “Transactions of the Association for Computational Linguistics” (TACL). Queste sono le “case” dove la ricerca più all’avanguardia viene pubblicata e discussa.
Perché tutto questo è importante? Le applicazioni pratiche
Ok, ma a cosa serve concretamente la linguistica computazionale? Beh, gli impatti sulla società sono enormi e in crescita. Pensiamo a:
- Sviluppo sostenibile: Analizzare documenti politici per trovare spunti sulle politiche di sostenibilità.
- Economia verde: Studiare i trend economici legati alla sostenibilità.
- Ricerca scientifica: Analizzare le tendenze e i temi emergenti in vari campi.
- Infrastrutture linguistiche: Creare dizionari, servizi di traduzione online, concordanze (strumenti che mostrano come una parola è usata in un testo) accessibili a tutti.
- Educazione: Questo è un punto chiave che abbiamo voluto approfondire! La linguistica computazionale sta rivoluzionando l’apprendimento:
- Sviluppo di applicazioni NLP per migliorare l’esperienza di apprendimento e analizzare le interazioni degli studenti.
- Creazione di sistemi di tutoraggio intelligenti e chatbot per supporto personalizzato.
- Implementazione di sistemi di valutazione automatica per dare feedback rapidi e consistenti.
- Strumenti per l’apprendimento delle lingue con feedback in tempo reale e percorsi adattivi.
Capire come si è sviluppata e cosa fa la linguistica computazionale ci permette di sfruttare al meglio il suo potenziale per migliorare la qualità della vita, dell’educazione e della ricerca.

La nostra lente d’ingrandimento: lo studio scientometrico
Proprio per capire meglio lo stato dell’arte, abbiamo deciso di fare uno studio *scientometrico*. Che parolona! In pratica, abbiamo analizzato quantitativamente la produzione scientifica nel campo della linguistica computazionale. Non studiamo la scienza in sé, ma i suoi “prodotti”: articoli, citazioni, collaborazioni. È come creare una mappa della conoscenza per vedere come si è sviluppato il campo, chi sono i protagonisti e quali sono i temi più caldi.
Abbiamo raccolto dati da tre database enormi: Scopus, Web of Science (WOS) e Lens. Parliamo di ben 81.740 documenti pubblicati tra il 1954 e il 2022! Abbiamo usato software specifici come CiteSpace e VOSviewer per analizzare questi dati e rispondere a domande come:
- Quanto si pubblica anno per anno?
- Quali sono i paesi, le università, le riviste e gli autori più produttivi?
- Quali sono i lavori più citati (e quindi influenti)?
- Quali sono gli argomenti e i temi più studiati?
Cosa abbiamo scoperto? I numeri parlano (Bibliometria)
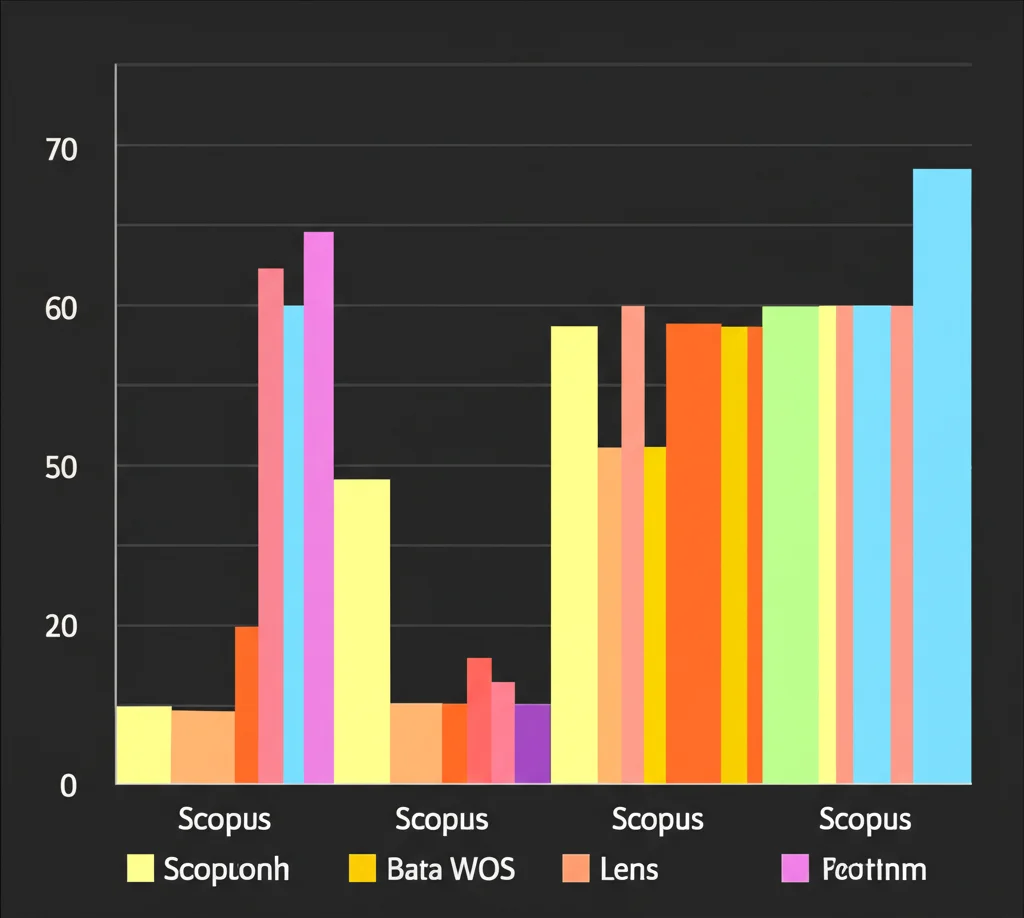
L’analisi bibliometrica ci ha dato un quadro chiaro:
- Crescita esponenziale: La produzione scientifica è aumentata tantissimo negli ultimi 20 anni, segno di un campo in piena espansione. Lens è il database con più documenti, seguito da WOS e Scopus.
- Leader mondiali: Gli Stati Uniti dominano la scena, seguiti da Germania e Regno Unito. Anche la Cina sta crescendo rapidamente. L’Italia c’è, anche se con numeri minori.
- Università al top: Istituzioni come la League of European Research Universities (LERU), l’Instituto Politécnico Nacional (Messico), l’Università di Edimburgo, Carnegie Mellon e l’Università della Pennsylvania sono tra le più attive.
- Dove si pubblica: La rivista “Computational Linguistics” è leader su WOS, mentre le serie “Lecture Notes in Computer Science” e “Lecture Notes in Artificial Intelligence” (Springer) dominano su Scopus e Lens. Molto importanti anche gli atti di conferenze (come quelle dell’ACL).
- Editori principali: MIT Press e Springer Nature sono i giganti dell’editoria nel campo.
- Aree di ricerca collegate: Ovviamente Informatica e Linguistica sono centrali, ma emergono anche Ingegneria, Scienze Sociali, Psicologia e Intelligenza Artificiale.
- Autori influenti: Nomi come Gelbukh, Sidorov, McNamara, Crossley e Gildea ricorrono spesso, anche se la lista varia un po’ a seconda del database.
I temi caldi e le connessioni nascoste (Scientometria)
Andando più a fondo con l’analisi scientometrica (co-citazioni, co-occorrenze di parole chiave), abbiamo identificato le tendenze e i temi più “caldi”:
- Parole chiave roventi: Termini come natural language processing (NLP), machine learning, artificial intelligence, information retrieval, text processing, sentiment analysis, deep learning, latent semantic analysis, grammar, e neural network sono tra i più citati e discussi recentemente.
- Visualizzazioni tematiche: Le mappe generate dai software mostrano cluster (gruppi) di argomenti interconnessi. NLP, machine learning e linguistica computazionale sono sempre al centro. Scopus tende a evidenziare applicazioni più informatiche (information retrieval, AI), WOS un mix tra teoria e pratica (linguistica, bibliometria), mentre Lens sembra più orientato a modelli cognitivi (concept formation, modelli psicologici).
- I lavori più influenti: Abbiamo identificato i 29 articoli/lavori più citati in assoluto nei tre database. Trattano temi come l’annotazione di corpora, l’analisi dell’apprendimento collaborativo, la sentiment analysis e modelli statistici come la Maximum Entropy.
Due filoni principali nella ricerca
Dall’analisi dei cluster di co-citazione, emergono chiaramente due macro-tendenze nella ricerca attuale:
1. Fondamenta e Metodologia: Un primo gruppo di ricerche (più evidente nei dati Scopus, con anni medi di pubblicazione tra 1981-2010) si concentra sui rapporti sullo stato dell’arte, sul progresso della teoria linguistica e sulla valutazione dell’affidabilità dei metodi (es. inter-coder agreement). È come se si stesse ancora consolidando la base teorica e metodologica.
2. Applicazioni Avanzate e Tecnologia: Un secondo gruppo (più visibile nei dati WOS, con anni medi 1999-2018) utilizza modelli linguistici probabilistici e tecnologie avanzate come il deep learning per affrontare problemi specifici: la disambiguazione del senso delle parole (word sense disambiguation), la misurazione della similarità semantica (semantic relatedness), l’identificazione dei ruoli semantici, la gestione delle espressioni referenziali e la traduzione automatica statistica. Qui siamo nel cuore delle applicazioni NLP più sofisticate.
Questa evoluzione mostra la maturità crescente del campo: dalle fondamenta alle applicazioni complesse, sfruttando le tecnologie più recenti.
Guardando al futuro: cosa ci aspetta?
Il nostro studio suggerisce diverse direzioni future eccitanti per la linguistica computazionale:
- Ancora più Deep Learning e IA: Integrare modelli IA sempre più avanzati per migliorare compiti NLP come la comprensione semantica profonda o la generazione di linguaggio naturale più fluida e contestualizzata.
- Applicazioni Interdisciplinari: Esplorare l’uso della linguistica computazionale in campi come la sanità (analisi di cartelle cliniche, interazione medico-paziente), l’interazione uomo-computer, le digital humanities.
- Solidità Teorica: Rafforzare le basi teoriche e metodologiche per rendere i modelli computazionali ancora più robusti e spiegabili.
- Multilinguismo Reale: Sviluppare sistemi NLP veramente multilingue e cross-lingue, superando le sfide poste dalle lingue con meno risorse digitali.
- Semantica e Traduzione: Affrontare le sfumature del significato, il contesto, le espressioni idiomatiche per migliorare la comprensione semantica e la traduzione automatica.
- Apprendimento Adattivo: Creare ambienti di apprendimento ancora più personalizzati e interattivi grazie all’NLP.
- Etica e Bias: Una sfida cruciale! Studiare e mitigare i bias presenti nei modelli linguistici per garantire equità e comprendere l’impatto socio-culturale di queste tecnologie.
- Collaborazione Globale: Favorire la condivisione di dati, strumenti e conoscenze a livello internazionale.
- Efficienza Computazionale: Rendere i modelli, spesso molto complessi, più leggeri ed efficienti per un uso pratico su larga scala.
E, naturalmente, dovremo tenere conto della recente esplosione dell’IA generativa (come i modelli GPT), che non era ancora pienamente riflessa nei nostri dati fino al 2022, ma che sta sicuramente rivoluzionando ulteriormente il panorama.
Qualche riflessione finale (e i limiti del nostro studio)
Fare studi scientometrici è utile, ma bisogna interpretare i risultati con cautela. È fondamentale usare più fonti di dati (come abbiamo fatto noi con Scopus, WOS e Lens) e diversi strumenti di analisi.
Dal nostro studio emergono due implicazioni pratiche importanti. Primo: bisogna promuovere lo studio della linguistica computazionale nelle università, non solo in informatica e linguistica, ma anche nelle scienze sociali, umanistiche e applicate. È uno strumento potentissimo! Secondo: bisogna pensare a come insegnarla in modo efficace, rendendola accessibile e stimolante, al di là degli aspetti tecnici più ostici.
Certo, il nostro studio ha dei limiti. Non abbiamo potuto approfondire ogni singolo tema emergente o analizzare nel dettaglio i metodi usati dai ricercatori. E, come detto, l’ondata dell’IA generativa degli ultimi anni meriterebbe un’analisi a sé.
Nonostante ciò, speriamo che questo viaggio nella linguistica computazionale, visto attraverso la lente della scientometria, vi abbia mostrato quanto sia un campo dinamico, in crescita e pieno di potenziale per il futuro. Unisce la profondità del linguaggio umano alla potenza del calcolo, aprendo scenari che fino a pochi decenni fa sembravano fantascienza.
Fonte: Springer





