COVID e Tempo: Perché i Modelli di Predizione a Volte Sbagliano? La Risposta nei Valori di Shapley
Ciao a tutti! Sono qui oggi per chiacchierare di qualcosa che mi ha davvero incuriosito durante e dopo la pandemia di COVID-19. Ricordate quei giorni intensi? Sembra ieri, eppure l’Organizzazione Mondiale della Sanità ha dichiarato la fine dell’emergenza sanitaria globale, lasciandoci però con cicatrici profonde e tante domande. Abbiamo visto oltre 773 milioni di casi confermati e milioni di vite spezzate. Una tragedia immane.
In questo caos, la tecnologia e l’intelligenza artificiale sono scese in campo. Abbiamo sviluppato modelli su modelli, software su software per cercare di prevedere, monitorare e capire cosa diavolo stesse succedendo. Uno degli obiettivi più gettonati era prevedere chi si sarebbe infettato e, purtroppo, chi non ce l’avrebbe fatta. Molti di questi modelli sembravano funzionare… all’inizio. Ma poi?
Il Tempo Mette i Bastoni tra le Ruote
Qui entra in gioco il fattore “tempo”, o come lo chiamano i tecnici, la temporalità. Pensateci: il virus non è rimasto lo stesso. Prima l’Alpha, poi la Delta, poi l’Omicron… ognuna con le sue caratteristiche, i suoi sintomi preferiti, la sua velocità di diffusione. L’Alpha faceva venire febbri alte e colpiva di più gli anziani. La Delta era più cattiva sui polmoni e più letale. L’Omicron, più simile a un’influenza, meno grave ma incredibilmente contagiosa.
Allora mi sono chiesto: cosa succede se prendo un modello di machine learning allenato con i dati del 2020, quando dominava l’Alpha, e provo a usarlo per fare previsioni nel 2022, in piena era Omicron? Intuitivamente, ci si aspetta che faccia più fatica, no? I dati di “allenamento” e quelli di “test” provengono da periodi diversi, con “regole del gioco” (le caratteristiche del virus e della malattia) leggermente cambiate.
La letteratura scientifica, infatti, suggeriva già che questi modelli non fossero sempre così robusti. A volte dicevano che gli anziani e le persone con malattie pregresse erano più a rischio, altre volte puntavano il dito sui giovani senza condizioni preesistenti. Insomma, un po’ di confusione. E soprattutto, si notava una differenza tra i modelli che prevedevano l’infezione e quelli che prevedevano la mortalità. Ma perché?
La Lente d’Ingrandimento: i Valori di Shapley
Per cercare di capirci qualcosa di più, ho deciso di usare uno strumento affascinante che arriva dalla teoria dei giochi, ma che è diventato un asso nella manica nell’interpretazione dei modelli di machine learning: i Valori di Shapley (o SHAP values). Immaginate il modello come una squadra che deve fare una previsione (es. “questa persona si infetterà” o “questa persona rischia di morire”). Ogni “giocatore” della squadra è una caratteristica del paziente: età, sesso, sintomi (febbre, tosse, mal di gola…), condizioni preesistenti (diabete, problemi cardiaci…), se è stato ricoverato, ecc.
I Valori di Shapley ci dicono, in modo equo e matematicamente solido, quanto ogni singolo “giocatore” (ogni caratteristica) ha contribuito alla previsione finale fatta dal modello per *quella specifica persona*. Un valore positivo alto per l'”età” significa che l’età avanzata ha spinto molto verso una previsione di rischio maggiore. Un valore negativo per la “tosse” significa che l’assenza di tosse ha contribuito a prevedere un rischio minore. Capire questo ci permette di “aprire la scatola nera” dei modelli e vedere cosa li guida davvero.
Ho preso un grosso database brasiliano (dello stato di Espírito Santo) con dati dal 2020 al 2022, quasi un milione di persone, e ho costruito modelli di previsione (usando principalmente Regressione Logistica e Random Forest) sia per l’infezione che per la mortalità. Poi, ho messo alla prova l’ipotesi della temporalità: ho allenato i modelli su un anno e li ho testati su un altro. E infine, ho usato i Valori di Shapley per ficcanasare nei meccanismi interni.

Prevedere l’Infezione: Un Bersaglio Mobile
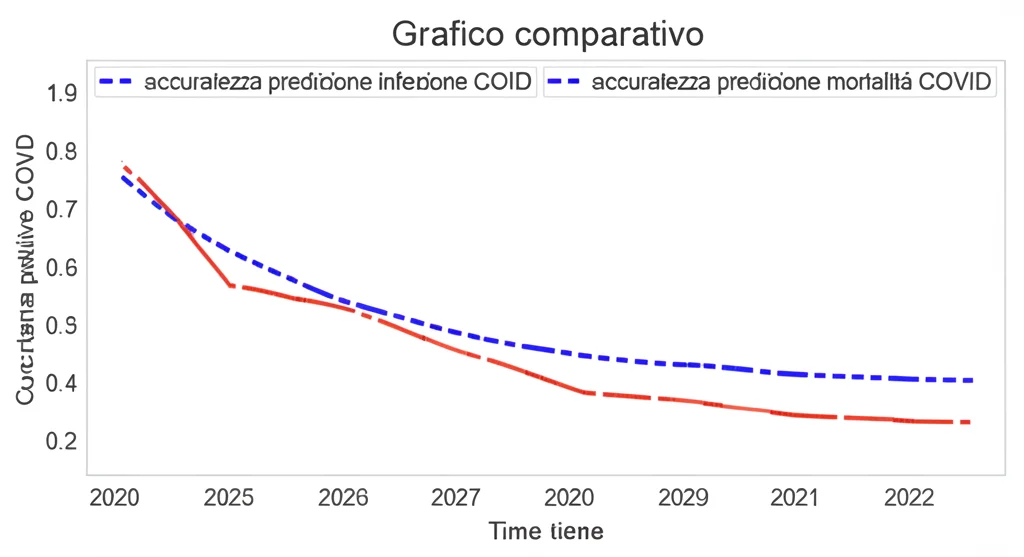
I risultati per i modelli di predizione dell’infezione hanno confermato i sospetti. Quando c’era un “salto temporale” tra i dati di allenamento e quelli di test (es. allenamento 2020, test 2021; oppure allenamento 2021, test 2022), l’accuratezza dei modelli calava. Non un crollo verticale, ma un calo sensibile e consistente. In media, si perdeva tra il 2.5% e il 4.3% di accuratezza.
E perché? I Valori di Shapley ci hanno dato la risposta. Guardando quali caratteristiche erano più importanti anno per anno, abbiamo visto che la classifica cambiava!
- Nel 2020 (era Alpha/originale), i pezzi grossi erano: febbre, età, tosse, livello di istruzione, sesso.
- Nel 2021 (era Delta), la classifica diventava: età, febbre, naso che cola, istruzione, etnia. La tosse perdeva importanza, emergeva il naso che cola.
- Nel 2022 (era Omicron), i più influenti erano: tosse, età, febbre, mal di gola, istruzione. Tornava la tosse, ma spuntava il mal di gola, mentre il naso che cola scendeva.
Vedete? Non c’era un gruppo fisso di “super-predittori” per l’infezione che valesse per tutti e tre gli anni. Le caratteristiche chiave cambiavano, probabilmente proprio a causa dei diversi sintomi portati dalle diverse varianti. Questo spiega perché i modelli facevano fatica a mantenere la stessa performance nel tempo: le “regole” per identificare un’infezione sembravano cambiare leggermente. La sensibilità dei modelli (la capacità di beccare i veri positivi) era particolarmente bassa e calava ancora di più con il gap temporale, specialmente nel 2022, forse perché i sintomi dell’Omicron erano più sfumati e simili all’influenza.
Prevedere la Mortalità: Roccia Solida
Passiamo ora ai modelli per la predizione della mortalità. Qui la storia è stata completamente diversa. Anche allenando il modello su un anno e testandolo su un altro, l’accuratezza rimaneva incredibilmente stabile e alta (attorno all’87%!). Il calo di performance dovuto al gap temporale era minimo, quasi trascurabile (tra l’1% e l’1.5%).
Di nuovo, i Valori di Shapley ci hanno svelato il perché di questa stabilità. Analizzando le caratteristiche più importanti anno per anno:
- Nel 2020: ricovero, età, distress respiratorio, comorbidità cardiaca, comorbidità diabetica.
- Nel 2021: ricovero, età, distress respiratorio, comorbidità cardiaca, tosse.
- Nel 2022: età, ricovero, distress respiratorio, comorbidità cardiaca, mal di testa.
Notate qualcosa? Le prime quattro caratteristiche – età, ricovero, distress respiratorio e comorbidità cardiaca – sono rimaste costantemente ai primissimi posti per tutti e tre gli anni! Certo, la quinta posizione cambiava, ma il grosso del lavoro di previsione era fatto sempre da quel nucleo di quattro fattori. E i loro Valori di Shapley erano molto più alti rispetto a tutte le altre caratteristiche, indicando che il loro contributo era dominante.
Questo spiega la robustezza dei modelli di mortalità: c’erano dei fattori di rischio potentissimi e stabili nel tempo che permettevano ai modelli di funzionare bene indipendentemente dal periodo specifico (e quindi dalla variante dominante). L’età avanzata, l’essere ricoverati, avere problemi respiratori gravi o problemi cardiaci preesistenti sono fattori di rischio così forti per l’esito infausto del COVID-19 che hanno continuato a pesare enormemente sulle previsioni per tutta la durata della pandemia considerata.
Cosa Ci Portiamo a Casa?
Questa piccola indagine ci lascia con alcune riflessioni importanti.
Primo: il tempo conta, eccome! Soprattutto quando si cerca di prevedere l’infezione da COVID-19. Usare un modello allenato su dati “vecchi” può portare a previsioni meno accurate. Per la mortalità, invece, questo problema sembra molto meno sentito, almeno nel periodo 2020-2022.
Secondo: i Valori di Shapley sono uno strumento potente per capire perché un modello funziona (o non funziona) e quanto è robusto. Ci hanno mostrato che la robustezza dipende dall’avere un set fisso di caratteristiche “dominanti” che guidano le previsioni in modo consistente nel tempo. Se queste caratteristiche cambiano, come nel caso dell’infezione, il modello diventa più instabile.
Terzo: questo ha implicazioni pratiche. Bisogna stare attenti a usare modelli predittivi senza considerare quando sono stati allenati. E per chi costruisce questi modelli, usare strumenti come Shapley può aiutare a capire meglio i propri “creaturi” digitali, a valutarne l’affidabilità e magari a migliorarli. Speriamo che una maggiore consapevolezza sulla stabilità e interpretabilità dei modelli ci aiuti ad affrontare meglio future crisi sanitarie.
Un Pizzico di Onestà: I Limiti
Come ogni studio, anche questo ha i suoi limiti. I dati provengono solo da uno stato brasiliano, quindi generalizzare a livello globale richiede cautela. Non abbiamo considerato direttamente l’impatto delle specifiche varianti o delle campagne vaccinali, che sicuramente hanno giocato un ruolo. Abbiamo usato principalmente due tipi di modelli (LR e RF), altri potrebbero dare risultati diversi. E abbiamo guardato a finestre temporali annuali, forse analisi più frequenti (settimanali o mensili) rivelerebbero altre dinamiche.
In Conclusione
La temporalità ha un impatto negativo sulla previsione dell’infezione da COVID-19, ma non su quella della mortalità, almeno nei dati analizzati. La chiave di questa differenza, svelata dai Valori di Shapley, sta nella stabilità delle caratteristiche più importanti: mutevoli per l’infezione, costanti per la mortalità (con età, ricovero, distress respiratorio e problemi cardiaci a farla da padrone). Un monito a usare i modelli di machine learning con consapevolezza del contesto temporale e un invito a usare strumenti come Shapley per capirli più a fondo.
Fonte: Springer