
Anguille Elettriche e AI: La Nuova Frontiera per Riconoscere i Generi Musicali!
Ciao a tutti! Oggi voglio parlarvi di qualcosa che mi appassiona tantissimo: la musica e come la tecnologia, in particolare l’intelligenza artificiale, sta cambiando il modo in cui la comprendiamo e la organizziamo. Avete mai pensato a quanto sia incredibilmente complesso, ma affascinante, cercare di etichettare un brano musicale? Rock, Jazz, Classica, Pop, Hip-Hop… i generi sono tantissimi, ognuno con le sue sfumature, la sua storia, la sua “anima”.
Perché è Difficile Classificare la Musica?
La musica è un fenomeno sociale in continua evoluzione. Ogni genere racconta qualcosa di una cultura, di un’epoca, di un gruppo di persone. Identificare il genere di una canzone non è banale. Certo, ci sono caratteristiche distintive – il ritmo, la melodia, gli strumenti usati – ma spesso le cose si complicano. Pensate a quanti sottogeneri e sotto-sottogeneri esistono oggi! A volte, anche per un orecchio esperto è una sfida.
La difficoltà sta anche nella soggettività: quello che per me è “rock alternativo”, per qualcun altro potrebbe essere semplicemente “indie rock”. Non c’è una definizione unica e universalmente accettata per ogni genere. E poi c’è la qualità audio, il rumore di fondo, le variazioni stilistiche all’interno dello stesso brano… insomma, un bel rompicapo!
I metodi tradizionali per classificare la musica si basavano sull’estrazione manuale di caratteristiche specifiche (temporali, spettrali, ecc.). Funzionavano, sì, ma avevano i loro limiti: richiedevano molta conoscenza specifica, erano sensibili al rumore e non sempre catturavano la vera essenza complessa della musica. Poi è arrivato il deep learning, con reti neurali come le CNN e le RNN, capaci di imparare le caratteristiche direttamente dai dati audio grezzi. Fantastico, vero? Però anche qui ci sono sfide: servono enormi quantità di dati etichettati, i costi computazionali sono alti e c’è sempre il rischio di “imparare troppo” solo dai dati di addestramento (il famoso overfitting).
La Nostra Idea: Un Mix Esplosivo di Tecnologie
Ed è qui che entra in gioco la nostra idea, un approccio un po’ diverso e, lasciatemelo dire, piuttosto ingegnoso! Abbiamo pensato: perché non combinare il meglio di diversi mondi? Abbiamo messo insieme tre componenti chiave:
- ZFNet (Zeiler and Fergus Network): Immaginatela come un “occhio esperto” allenato. È una rete neurale convoluzionale (CNN) pre-addestrata, bravissima a riconoscere pattern complessi. Noi l’abbiamo adattata per “vedere” le caratteristiche importanti nei segnali audio, trasformati in immagini chiamate Mel-spettrogrammi o rappresentati come coefficienti MFCC.
- ELM (Extreme Learning Machines): Questo è il nostro “classificatore fulmineo”. È un tipo di rete neurale con uno strato nascosto che impara in modo incredibilmente veloce ed efficiente, senza tutti i complessi aggiustamenti richiesti dalle reti tradizionali. Prende le caratteristiche estratte da ZFNet e decide a quale genere appartiene la musica.
- MEEFO (Modified Electric Eel Foraging Optimizer): E qui arriva la parte più “selvaggia”! Questo è un algoritmo di ottimizzazione ispirato alla natura, in particolare al comportamento di caccia delle anguille elettriche. Sì, avete capito bene! Lo usiamo per “accordare” finemente i parametri dell’ELM, rendendo l’intero sistema ancora più performante. È una versione modificata e potenziata di un algoritmo esistente (EEFO), pensata per essere più robusta ed efficiente.
L’idea è che ZFNet estrae le informazioni cruciali, ELM classifica rapidamente e MEEFO si assicura che ELM lavori al meglio delle sue possibilità. Un vero lavoro di squadra!

MEEFO: L’Algoritmo Ispirato alle Anguille Elettriche
Lasciatemi spendere due parole in più su MEEFO, perché è davvero affascinante. Le anguille elettriche sono cacciatrici incredibili. Usano scariche elettriche a basso voltaggio per orientarsi e individuare le prede (hanno una vista limitata) e scariche ad alto voltaggio per stordirle. Ma la cosa ancora più interessante scoperta di recente è che cacciano in gruppo!
Si radunano, nuotano in cerchio per radunare i pesci in una “palla di prede” e poi lanciano un attacco coordinato ad alto voltaggio. Comunicano tra loro, si riposano, migrano e cacciano insieme. L’algoritmo EEFO originale cercava di modellare matematicamente queste fasi:
- Interazione: Le “anguille” (soluzioni candidate nel nostro algoritmo) comunicano e condividono informazioni sulla loro posizione nello spazio di ricerca (esplorazione).
- Riposo: Si concentrano su aree promettenti per affinare la ricerca localmente.
- Caccia: Intensificano la ricerca nelle zone dove si trovano le soluzioni migliori finora (sfruttamento).
- Migrazione: Si spostano tra le fasi di esplorazione e sfruttamento per evitare di rimanere bloccate in soluzioni non ottimali.
La nostra versione modificata (MEEFO) aggiunge un paio di assi nella manica: usa delle “mappe caotiche” per migliorare la casualità e l’esplorazione dello spazio di ricerca e introduce una “fase di eliminazione” per scartare le soluzioni meno promettenti e concentrarsi su quelle migliori. Questo rende l’algoritmo più robusto e capace di trovare parametri ottimali per il nostro classificatore ELM, bilanciando perfettamente l’esplorazione di nuove possibilità e lo sfruttamento delle soluzioni già trovate.
Mettiamo alla Prova il Sistema!
Ovviamente, non basta avere una bella idea, bisogna vedere se funziona! Abbiamo preso due “campi di battaglia” ben noti nel mondo della ricerca sulla classificazione musicale: i dataset GTZAN e Ballroom.
- GTZAN: Contiene 1000 tracce audio di 30 secondi, divise equamente in 10 generi (Blues, Classica, Country, Disco, Hip-hop, Jazz, Metal, Pop, Reggae, Rock). È un classico, anche se ha qualche limite (qualità non eccelsa, qualche etichetta forse errata).
- Ballroom: Ha 698 tracce di circa 20 secondi, divise in 8 generi da sala da ballo (Cha-Cha-Cha, Jive, Quickstep, Rumba, Samba, Tango, Valzer Viennese, Valzer). Anche questo è molto usato, ma presenta sfide simili a GTZAN.
Abbiamo trasformato le tracce audio usando due tecniche popolari:
- Mel-spettrogrammi: Sono come “fotografie” del suono che mostrano come l’intensità delle diverse frequenze (su una scala che imita l’udito umano, la scala Mel) cambia nel tempo. Abbiamo usato una finestra di 512 campioni e 128 “bidoni” Mel per un buon compromesso tra dettaglio e complessità.
- MFCC (Mel-Frequency Cepstral Coefficients): Sono un altro modo per rappresentare le caratteristiche spettrali del suono, molto usati nel riconoscimento vocale e musicale.
Abbiamo quindi dato queste rappresentazioni in pasto al nostro sistema ZFNet/ELM/MEEFO e abbiamo confrontato i risultati con quelli di altri modelli all’avanguardia, come MusicRecNet, PRCNN, RNN-LSTM, ResNet-50, VGG-16 e DNN.

I Risultati? Sorprendenti!
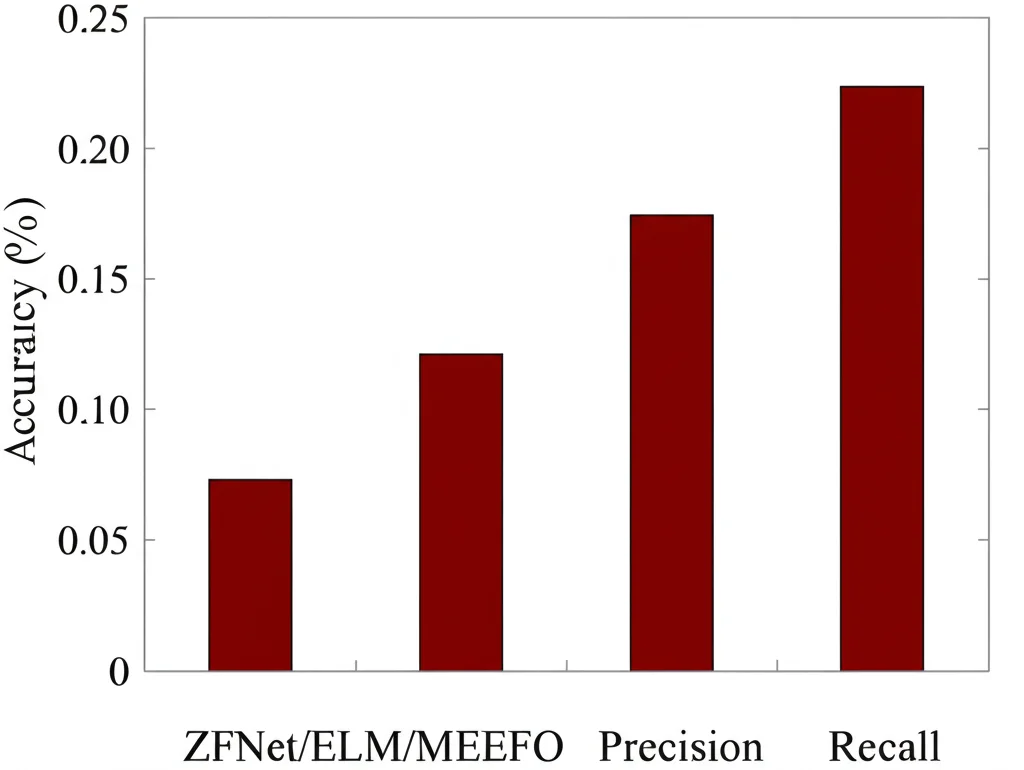
Ebbene, i risultati sono stati davvero incoraggianti! Il nostro approccio ZFNet/ELM/MEEFO ha ottenuto punteggi molto alti in termini di accuratezza (quante canzoni classifica correttamente in totale), precisione (quante delle canzoni etichettate come un certo genere appartengono davvero a quel genere) e recall (quante canzoni di un certo genere vengono effettivamente identificate come tali).
In particolare, il nostro modello ha mostrato un recall eccezionale, sfiorando il 99.50%! Significa che riesce a “pescare” quasi tutte le canzoni del genere giusto. L’accuratezza e la precisione si sono attestate intorno al 98.20%, superando la maggior parte degli altri metodi con cui ci siamo confrontati sui dataset GTZAN e Ballroom. Abbiamo anche notato che usare gli MFCC come input ha dato risultati leggermente migliori rispetto ai Mel-spettrogrammi.
Abbiamo fatto anche degli “studi di ablazione”, cioè abbiamo provato a togliere uno dei componenti (ZFNet, ELM o MEEFO) per vedere cosa succedeva. E indovinate? Le prestazioni calavano! Questo conferma che è proprio la combinazione sinergica di questi tre elementi a fare la differenza: ZFNet estrae le feature giuste, ELM classifica velocemente e MEEFO ottimizza il tutto alla perfezione. Abbiamo anche usato test statistici (il test di Wilcoxon) per confermare che i miglioramenti ottenuti non erano dovuti al caso, ma erano statisticamente significativi rispetto a molti altri approcci.
Certo, dobbiamo essere onesti: i dataset usati hanno i loro limiti (sono piccoli, un po’ datati, focalizzati sulla musica occidentale). Modelli più “profondi” come ResNet-50 potrebbero, su dataset enormi e diversificati, catturare sfumature ancora più complesse. Inoltre, MEEFO, pur essendo efficiente, può richiedere un certo tempo di calcolo per l’ottimizzazione. Ma il nostro approccio offre un eccellente equilibrio tra prestazioni ed efficienza, rendendolo molto promettente.
Cosa Significa Tutto Questo e Dove Andiamo Ora?
Questa ricerca apre porte interessanti. Un sistema più accurato per identificare i generi musicali può migliorare tantissime cose:
- Raccomandazioni musicali: Immaginate playlist ancora più personalizzate!
- Ricerca musicale: Trovare brani simili a quello che ci piace diventa più facile.
- Analisi musicale: Musicologi e ricercatori possono avere strumenti più potenti.
- Educazione musicale: Aiutare gli studenti a capire le caratteristiche dei diversi generi.
Il nostro lavoro è un passo avanti in questa direzione, mostrando come la combinazione intelligente di deep learning e algoritmi bio-ispirati possa portare a risultati notevoli.
Cosa faremo dopo? Beh, le idee non mancano! Vogliamo testare il nostro modello su dataset più grandi e variegati, includere una gamma più ampia di generi musicali (magari anche di nicchia o non occidentali) ed esplorare l’uso di caratteristiche audio ancora più complesse. Chissà, potremmo anche sperimentare con altre tecniche di deep learning o altri algoritmi metaheuristici.
Insomma, il viaggio nel mondo dell’intelligenza artificiale applicata alla musica è appena iniziato e noi siamo entusiasti di farne parte, magari scoprendo che anche le anguille elettriche possono insegnarci qualcosa su come ascoltare e capire meglio la colonna sonora delle nostre vite!
Fonte: Springer





