Vision Transformer e Lupi Grigi Digitali: L’IA che Vede la Gravità del COVID-19 come Mai Prima!
Ciao a tutti! Oggi voglio parlarvi di qualcosa che mi appassiona moltissimo e che sta cambiando il modo in cui affrontiamo le sfide mediche: l’intelligenza artificiale applicata alla diagnostica per immagini. In particolare, ci tufferemo in un progetto affascinante che utilizza tecnologie all’avanguardia per “vedere” e classificare la gravità del COVID-19 analizzando radiografie del torace (CXR) e scansioni TC (Tomografia Computerizzata). Sembra fantascienza, vero? Eppure è realtà, e i risultati sono sbalorditivi!
La Sfida: Capire la Gravità del COVID-19 dalle Immagini
Come ben sappiamo, la pandemia di COVID-19 ha messo a dura prova i sistemi sanitari globali. Una delle maggiori sfide è stata valutare rapidamente e accuratamente la gravità dell’infezione polmonare in ogni paziente. Le immagini mediche, come le radiografie e le TC, sono diventate strumenti fondamentali. Le CXR sono veloci, accessibili, ottime per monitorare i pazienti in terapia intensiva, ma a volte faticano a cogliere i dettagli più fini, specialmente nelle fasi iniziali o nei casi lievi. Le TC, invece, sono incredibilmente dettagliate e sensibili, capaci di scovare anche le più piccole opacità a “vetro smerigliato” (le famose GGO) o consolidamenti tipici del COVID-19. Permettono una valutazione quantitativa del danno polmonare, spesso usando punteggi come il CT-SS (CT severity score).
Il problema? Interpretare queste immagini richiede tempo, esperienza e può essere soggetto a variabilità. Inoltre, durante un picco pandemico, i radiologi possono essere sopraffatti. Qui entra in gioco l’IA.
L’IA Tradizionale (CNN) e i Suoi Limiti
Negli ultimi anni, abbiamo visto un boom di modelli di deep learning, soprattutto le Reti Neurali Convoluzionali (CNN), applicate all’analisi di immagini mediche. Modelli come ResNet, VGG, AlexNet hanno dimostrato di poter distinguere tra immagini di polmoni sani, affetti da COVID-19 o altre polmoniti con buona precisione. Funzionano un po’ come degli occhi digitali che imparano a riconoscere pattern specifici (features) nelle immagini.
Tuttavia, le CNN hanno un “difetto”: tendono a concentrarsi su aree locali dell’immagine, grazie ai loro “campi recettivi” limitati. È come guardare il mondo attraverso una cannuccia: vedi bene i dettagli vicini, ma perdi la visione d’insieme. Per analizzare strutture complesse e diffuse come i polmoni, dove le lesioni possono essere sparse e le relazioni a lunga distanza tra diverse aree sono importanti, questo può essere un limite.
La Rivoluzione dei Vision Transformer (ViT)
Ed è qui che arriva la star del nostro show: il Vision Transformer (ViT). Nato nel campo dell’elaborazione del linguaggio naturale, questo tipo di architettura è stato adattato con successo all’analisi delle immagini, e sta facendo faville! Come funziona? Immaginate di dividere l’immagine in tanti piccoli pezzi, come un puzzle (questi pezzi si chiamano “patch”). Il ViT, grazie a un meccanismo potentissimo chiamato “auto-attenzione” (self-attention), è in grado di valutare l’importanza di *ogni* pezzo rispetto a *tutti* gli altri, simultaneamente.
In pratica, il ViT non guarda solo localmente, ma cattura le relazioni globali all’interno dell’immagine. È come avere una visione panoramica e capire come ogni dettaglio si collega al quadro generale. Questo è fondamentale per le immagini mediche, dove sottili pattern distribuiti su vaste aree possono indicare la gravità di una malattia come il COVID-19. Diversi studi hanno già mostrato come i ViT superino le CNN in compiti di classificazione e valutazione della gravità del COVID-19 da CXR e TC.

Ma C’è di Più: Ottimizzare la Bestia!
I ViT sono potenti, ma anche “affamati” di dati e risorse computazionali. Inoltre, per farli rendere al meglio, bisogna scegliere attentamente i loro “iperparametri”: quanti strati usare, la dimensione delle patch, il numero di “teste di attenzione”, ecc. È un po’ come accordare uno strumento musicale complesso: una piccola modifica può fare una grande differenza.
Qui entra in gioco la seconda parte innovativa del nostro approccio: gli ottimizzatori metaeuristici. Invece di provare combinazioni a caso o usare metodi standard, abbiamo usato algoritmi ispirati alla natura per trovare le impostazioni perfette per il nostro ViT e per selezionare le caratteristiche (features) più importanti estratte dal modello.
- Grey Wolf Optimizer (GWO): Immaginate un branco di lupi grigi che cacciano insieme. C’è un leader (alpha), dei vice (beta), degli esploratori (delta) e gregari (omega). Il GWO simula questa gerarchia sociale e le strategie di caccia per esplorare lo spazio delle possibili configurazioni degli iperparametri del ViT e convergere verso la soluzione migliore (quella che minimizza l’errore di classificazione). L’abbiamo usato per “accordare” il nostro ViT.
- Particle Swarm Optimization (PSO): Pensate a uno stormo di uccelli o uno sciame di api che cercano cibo. Ogni “particella” (uccello/ape) si muove nello spazio delle soluzioni, ricordando la posizione migliore trovata da sé e quella migliore trovata dall’intero sciame. Il PSO imita questo comportamento collettivo per selezionare, tra tutte le features estratte dal ViT ottimizzato, solo quelle veramente discriminanti per la classificazione della gravità, eliminando il “rumore” e rendendo il modello più efficiente e accurato.
Il Nostro Framework Ibrido: GWO_ViT_PSO_MLP
Mettendo insieme tutti questi pezzi, abbiamo creato un framework ibrido che ho chiamato, con poca fantasia ma molta chiarezza, GWO_ViT_PSO_MLP. Ecco come funziona in sequenza:
1. Il GWO ottimizza gli iperparametri del ViT.
2. Il ViT ottimizzato analizza le immagini (CXR o CT) ed estrae un set ricco di features globali e locali.
3. Il PSO seleziona da questo set solo le features più significative, riducendo la dimensionalità.
4. Un classificatore MLP (Multi-Layer Perceptron), anch’esso ottimizzato, prende queste features super-selezionate e classifica l’immagine in base alla gravità del COVID-19 (Normale, Lieve, Moderata, Severa).
Ma non è finita qui! Ci siamo resi conto che distinguere tra casi lievi e moderati è particolarmente difficile. Perciò, abbiamo implementato una strategia di classificazione multi-fase:
- Fase 1: Distingue i casi Normali da tutti i casi COVID-19 (Lieve+Moderato+Severo).
- Fase 2: Separa i casi Severi da quelli Lievi e Moderati.
- Fase 3: Si concentra sulla sfida più difficile: distinguere i casi Lievi da quelli Moderati.
Questo approccio “divide et impera” permette al modello di specializzarsi in compiti più semplici, migliorando l’accuratezza complessiva. Per definire oggettivamente le classi di gravità nelle radiografie, abbiamo usato le maschere di segmentazione fornite nel dataset COVID-QU-Ex per calcolare l’Extent of Infection (EI), ovvero il rapporto tra l’area infetta e l’area totale dei polmoni (Lieve 50%).

Risultati da Urlo!
E ora, i numeri che contano. Abbiamo testato il nostro GWO_ViT_PSO_MLP su due dataset principali: uno di radiografie (COVID-QU-Ex) e uno di TC. I risultati sono stati eccezionali, superando nettamente sia le CNN tradizionali che i ViT standard non ottimizzati.
Guardate qui:
- Classificazione a 2 classi (Normale vs COVID) su CXR: Il nostro modello ha raggiunto un’accuratezza del 99.14%!
- Classificazione a 2 classi (Normale vs COVID) su CT: Accuratezza del 98.89%!
- Classificazione a 4 classi (Normale, Lieve, Moderata, Severa) su CXR: Accuratezza dell’87.84%, molto superiore a ResNet34 (84.22%) e VGG19 (82.64%).
- Classificazione a 3 classi (Lieve, Moderata, Severa) su CXR: Accuratezza dell’89.74%.
Anche nelle fasi più difficili della classificazione multi-fase, come distinguere tra Lieve e Moderato (Fase 3), il nostro approccio ha mostrato miglioramenti significativi, raggiungendo un’accuratezza del 91.45%, laddove i modelli tradizionali faticavano molto di più.
L’ottimizzazione con GWO e PSO ha anche permesso di ridurre la dimensione delle features utilizzate (da 768 a circa 220-250), rendendo il modello finale più leggero ed efficiente senza sacrificare la precisione.
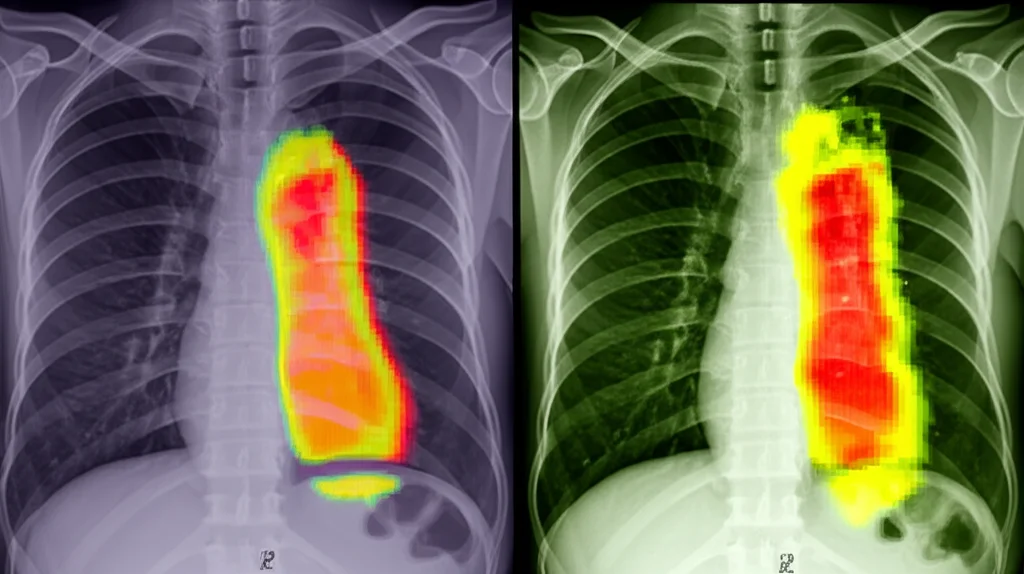
Capire Perché Funziona: Grad-CAM
Un aspetto fondamentale dell’IA in medicina è la trasparenza. Vogliamo capire *perché* il modello prende una certa decisione. Per questo, abbiamo usato una tecnica chiamata Grad-CAM (Gradient-weighted Class Activation Mapping). Questa tecnica genera delle “mappe di calore” sull’immagine originale, evidenziando le aree che il modello ha considerato più importanti per la sua classificazione.
Le visualizzazioni Grad-CAM hanno confermato che il nostro modello si concentra sulle regioni polmonari rilevanti: aree più piccole e localizzate per i casi lievi, aree più estese e diffuse per i casi moderati e severi. Questo non solo aumenta la nostra fiducia nel modello, ma potrebbe anche fornire ai medici indicazioni visive utili.
Conclusioni e Prospettive Future
Cosa ci portiamo a casa da questa ricerca? Che l’integrazione intelligente di architetture potenti come i Vision Transformer con tecniche di ottimizzazione metaeuristica come GWO e PSO può davvero fare la differenza nella classificazione della gravità del COVID-19 da immagini mediche. Il nostro framework GWO_ViT_PSO_MLP ha dimostrato un’accuratezza e un’efficienza superiori rispetto agli approcci esistenti, specialmente nei compiti di classificazione multi-classe e nella gestione di casi difficili da distinguere.
Questo apre porte entusiasmanti per lo sviluppo di strumenti di supporto decisionale clinico più affidabili, veloci e automatizzati. Certo, ci sono ancora sfide, come ridurre ulteriormente i costi computazionali dei ViT per renderli accessibili ovunque e migliorare ancora la distinzione tra i casi più sfumati.
Il futuro potrebbe vedere l’uso di varianti ViT più leggere o l’estensione di questo approccio ad altre patologie e modalità di imaging. La strada è tracciata, e sono convinto che l’IA continuerà a rivoluzionare la medicina, aiutandoci a “vedere” sempre più chiaramente dentro il corpo umano.
Spero che questo viaggio nel mondo dell’IA per la diagnosi del COVID-19 vi sia piaciuto! È un campo in continua evoluzione, e non vedo l’ora di vedere cosa ci riserverà il futuro.
Fonte: Springer





