
IA Spiegabile White-Box: Apriamo la Scatola Nera della Sicurezza di Rete!
Ciao a tutti! Oggi voglio parlarvi di qualcosa che mi appassiona tantissimo e che sta cambiando le carte in tavola nel mondo della sicurezza informatica: l’Intelligenza Artificiale Spiegabile (XAI), e in particolare i metodi cosiddetti “white-box”. Viviamo in un’era digitale dove le intrusioni nelle reti sono all’ordine del giorno, sempre più sofisticate e difficili da comprendere. L’IA ci dà una mano enorme nel rilevare queste minacce con i Sistemi di Rilevamento delle Intrusioni di Rete (NIDS), ma c’è un “ma”.
Spesso, questi sistemi basati su IA, specialmente quelli più potenti come le Reti Neurali Profonde (DNN), funzionano come delle “scatole nere” (black-box). Fanno il loro lavoro egregiamente, identificano attacchi che magari un umano non vedrebbe, ma quando chiediamo loro: “Ehi, IA, perché hai classificato questo traffico come sospetto?”, spesso alzano le spalle (metaforicamente, ovvio!). E questo, per un analista di sicurezza, è un bel grattacapo. Come ci si può fidare ciecamente di una decisione se non se ne capisce il motivo? Come si può migliorare il sistema se non si sa dove ha sbagliato o perché ha funzionato?
La Magia dell’XAI: Fare Luce nell’Oscurità
È qui che entra in gioco l’XAI. L’obiettivo è rendere queste decisioni dell’IA trasparenti, comprensibili. Immaginate di poter “aprire” la scatola nera e vedere i meccanismi interni, capire quali dati, quali caratteristiche del traffico di rete hanno portato l’IA a lanciare l’allarme. Questo non solo aumenta la fiducia nel sistema, ma permette agli analisti di lavorare meglio, più velocemente e con maggiore precisione.
Recentemente, con il mio team (parlo in prima persona plurale perché la ricerca è uno sforzo collettivo!), ci siamo concentrati sull’applicazione e la valutazione di tecniche XAI specifiche, chiamate white-box. A differenza delle tecniche black-box (come LIME o SHAP, magari ne avete sentito parlare), che cercano di capire il modello “da fuori” osservando solo input e output, le tecniche white-box hanno accesso diretto all’architettura interna e ai parametri del modello IA. È come avere gli schemi del motore invece di provare a capire come funziona solo ascoltandone il rumore!
Questo accesso privilegiato rende le spiegazioni generate dai metodi white-box potenzialmente più accurate e affidabili, perché non si basano su approssimazioni ma sull’analisi diretta del modello stesso. Certo, c’è un piccolo “prezzo” da pagare: questi metodi sono spesso specifici per determinati tipi di modelli IA. Nel nostro caso, ci siamo focalizzati su quelli applicabili alle reti neurali, che sono potentissime per la NIDS.
I Nostri “Supereroi” White-Box: LRP, IG e DeepLift
Abbiamo messo sotto la lente d’ingrandimento tre metodi white-box molto promettenti e utilizzati nel campo delle reti neurali:
- Layer-wise Relevance Propagation (LRP): Immaginate che l’output della rete (la decisione finale) sia una certa quantità di “rilevanza”. LRP la propaga all’indietro, strato per strato, fino agli input, distribuendola in modo che ogni caratteristica in ingresso ottenga un punteggio che indica quanto ha contribuito alla decisione finale. Mantiene un principio di conservazione: la somma della rilevanza rimane costante.
- DeepLift: Segue un principio simile a LRP, ma aggiunge delle regole su come distribuire questa rilevanza, basandosi sulla differenza rispetto a un input di “riferimento” (una sorta di baseline).
- Integrated Gradients (IG): Questo metodo guarda ai gradienti (la “pendenza” della funzione di decisione) lungo il percorso tra un input di riferimento e l’input effettivo. In pratica, calcola quanto ogni caratteristica contribuisce al cambiamento dell’output rispetto alla baseline, rispettando principi come la sensibilità (se una feature conta, deve avere un contributo non nullo) e l’invarianza all’implementazione (modelli diversi che fanno la stessa cosa dovrebbero avere spiegazioni simili).

Mettere alla Prova l’XAI: Il Nostro Framework di Valutazione
Ok, abbiamo questi metodi fantastici, ma come facciamo a sapere quanto sono *davvero* bravi nel contesto della sicurezza di rete? Non basta dire “funzionano”. Dobbiamo misurarli! Per questo, abbiamo sviluppato un framework di valutazione end-to-end, prendendo spunto da lavori precedenti ma adattandolo specificamente per la NIDS.
Abbiamo definito sei metriche chiave per valutare questi metodi XAI, coprendo sia aspetti legati all’IA che requisiti specifici della sicurezza:
- Accuratezza Descrittiva (Descriptive Accuracy): Se l’XAI dice che certe feature sono super importanti per rilevare un attacco, cosa succede all’accuratezza del modello IA se le togliamo? Se l’accuratezza crolla, significa che l’XAI ha identificato correttamente le feature cruciali. Più il calo è netto, maggiore è il “potere esplicativo” dell’XAI.
- Sparsità (Sparsity): La spiegazione fornita dall’XAI si concentra su poche feature chiave (alta sparsità) o si disperde su molte (bassa sparsità)? Idealmente, vorremmo spiegazioni “sparse”, più facili da interpretare per un analista che non deve così controllare decine di parametri.
- Stabilità (Stability): Se eseguo l’analisi XAI più volte sullo stesso campione, ottengo sempre la stessa spiegazione o risultati altalenanti? La coerenza è fondamentale per costruire fiducia. Vogliamo metodi stabili!
- Efficienza (Efficiency): Quanto tempo impiega il metodo XAI a generare una spiegazione? In scenari reali, specialmente durante un attacco, la velocità è essenziale. Un metodo troppo lento, per quanto accurato, potrebbe essere poco pratico.
- Robustezza (Robustness): Qui le cose si fanno serie. Un metodo XAI è robusto se continua a dare spiegazioni corrette anche se i dati di input sono leggermente “disturbati” o manipolati, magari da un attaccante che cerca di mascherare le sue tracce o ingannare il sistema. Abbiamo testato questo aspetto simulando attacchi avversari specifici contro le spiegazioni XAI.
- Completezza (Completeness): Il metodo XAI è in grado di fornire una spiegazione valida per *ogni* possibile campione di traffico di rete, inclusi i casi limite o anomali? Un metodo incompleto potrebbe essere sfruttato dagli hacker. Qui i metodi white-box hanno un vantaggio teorico: conoscendo il modello, dovrebbero essere intrinsecamente completi. Una spiegazione errata implicherebbe un problema nel modello stesso, non nell’approssimazione dell’XAI (come potrebbe accadere con i black-box).
I Campi di Battaglia: I Dataset
Per testare LRP, IG e DeepLift con le nostre metriche, abbiamo usato tre dataset molto noti e significativi nel campo della NIDS:
- NSL-KDD: Un classico, una versione migliorata del vecchio dataset KDD, ampiamente usato come benchmark.
- CICIDS-2017: Un altro benchmark importante, sviluppato più recentemente, con pattern di attacco variegati e realistici.
- RoEduNet-SIMARGL2021: Il più recente dei tre, particolarmente prezioso perché include traffico di rete realistico calcolato da dati live, oltre a simulazioni.
Per ciascun dataset, abbiamo addestrato modelli DNN e poi applicato i tre metodi XAI per generare spiegazioni sia a livello locale (per un singolo campione di traffico) che globale (per l’insieme dei dati).

I Risultati: Cosa Abbiamo Scoperto?
E ora, il momento della verità! Come si sono comportati i nostri campioni white-box? Ecco alcuni highlight:
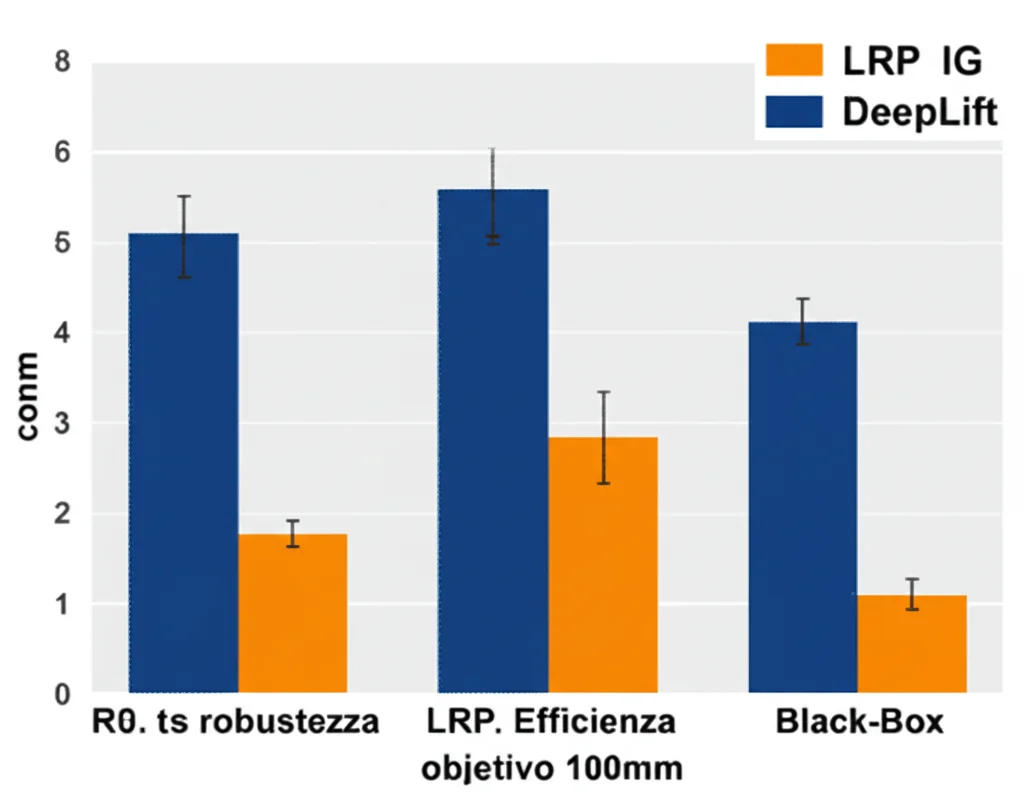
- Robustezza e Completezza: Punti di Forza White-Box! Come sospettavamo, i metodi white-box hanno mostrato i muscoli in queste due aree. Sono risultati significativamente più robusti agli attacchi avversari rispetto ai metodi black-box che avevamo analizzato in studi precedenti. Anche se abbiamo eseguito comunque i test di completezza (nonostante la loro natura intrinsecamente completa), i risultati hanno confermato la loro superiorità rispetto ai black-box, riuscendo a fornire spiegazioni valide per una percentuale molto alta di campioni, anche con perturbazioni limitate. Questo è cruciale per la fiducia in ambito security.
- Accuratezza Descrittiva e Sparsità: Qui LRP e IG hanno spesso avuto la meglio su DeepLift, mostrando curve di accuratezza che scendevano più nettamente rimuovendo le feature importanti e concentrando la spiegazione su un numero minore di feature (maggiore sparsità). Questo suggerisce che identificano in modo più efficace gli elementi davvero determinanti.
- Stabilità: I risultati sulla stabilità sono stati buoni, specialmente a livello locale. A livello globale, le performance erano simili tra i metodi, anche se LRP ha mostrato un leggero vantaggio sul dataset CICIDS-2017.
- Efficienza: LRP e IG sono risultati molto efficienti, generando spiegazioni in tempi rapidi anche per migliaia di campioni. DeepLift, invece, ha mostrato un aumento considerevole del tempo di calcolo all’aumentare dei campioni, rendendolo meno adatto per analisi globali su larga scala in tempo reale, anche se rimane ottimo per analisi locali. Abbiamo anche trovato un modo per aggirare parzialmente questa limitazione usando il multi-threading.
- Confronto Generale White vs. Black: Tirando le somme rispetto ai nostri studi precedenti sui metodi black-box (LIME e SHAP), i metodi white-box (LRP, IG, DeepLift) esaminati qui sono risultati complessivamente superiori o comparabili in quasi tutte le metriche, in particolare robustezza, completezza ed efficienza (per LRP/IG). L’unica metrica dove i black-box a volte primeggiavano era la stabilità globale in certi scenari. Questo ci porta a consigliare l’uso di metodi white-box quando possibile (cioè, quando si ha accesso al modello e si usano reti neurali).
L’Approccio Ibrido: Il Meglio dei Due Mondi?
Ci siamo anche chiesti: e se provassimo a combinare le spiegazioni white-box e black-box? Abbiamo abbozzato un framework ibrido. I risultati preliminari sono interessanti: in alcuni casi (come l’accuratezza descrittiva), l’ibrido sembra ereditare i punti di forza di entrambi. Tuttavia, per metriche come la robustezza e la completezza, l’approccio ibrido sarebbe limitato dall’anello più debole (il metodo black-box). È una direzione intrigante per ricerche future.
Limiti e Prossimi Passi: La Strada è Ancora Lunga (ma Promettente!)
Siamo entusiasti dei risultati, ma siamo anche i primi a dire che c’è ancora lavoro da fare. Abbiamo incontrato alcune limitazioni tecniche (ad esempio, problemi di memoria con IG/LRP nei test di completezza più stressanti, o l’impossibilità di usare la funzione softmax con alcuni pacchetti). Inoltre, sebbene la robustezza sia migliorata, i test mostrano che anche i metodi white-box non sono invulnerabili al 100% ad attacchi avversari mirati alle spiegazioni. Questo è un campanello d’allarme per la comunità: dobbiamo continuare a lavorare per rendere queste tecniche ancora più sicure prima di un’adozione su larga scala in ambienti critici.
Cosa ci riserva il futuro? Sicuramente testare il nostro framework su altri dataset e con altri tipi di modelli IA. Esplorare ulteriormente metodi white-box meno noti (come PatternNet, GradCAM, etc.). E, cosa fondamentale, lavorare sull’esperienza utente. Come presentare queste spiegazioni agli analisti di sicurezza in modo che siano davvero utili e intuitive? Magari combinando XAI con IA generativa per produrre report in linguaggio naturale? Abbiamo già fatto qualche esperimento in passato e pensiamo sia una direzione cruciale.
Conclusione: Verso una Cybersecurity più Trasparente e Affidabile
Insomma, il viaggio nell’IA Spiegabile applicata alla sicurezza di rete è appena iniziato, ma è incredibilmente promettente. I metodi white-box come LRP, IG e DeepLift rappresentano un passo avanti significativo per aprire quelle “scatole nere” e capire cosa succede davvero dentro i nostri sistemi di difesa basati su IA. Il nostro lavoro di valutazione comparativa, basato su metriche solide e dataset rilevanti, speriamo possa contribuire a spingere questo campo, fornendo strumenti e conoscenze utili alla comunità.
L’obiettivo finale? Costruire sistemi di sicurezza non solo intelligenti ed efficaci, ma anche trasparenti, affidabili e degni della nostra fiducia. E rendere il lavoro degli analisti di sicurezza un po’ meno frustrante e un po’ più potente. Credo fermamente che l’XAI sia una delle chiavi per raggiungere questo traguardo. E non vediamo l’ora di continuare a esplorare!
Ah, dimenticavo! Se siete curiosi e volete “sporcarvi le mani”, abbiamo reso disponibile il codice sorgente del nostro framework di valutazione. La scienza è condivisione, no?
Fonte: Springer





