
Strade Scivolose o Buio Pesto? La Nostra IA Vede Tutto per la Guida Autonoma!
Ciao a tutti! Sono qui per raccontarvi di una sfida affascinante nel mondo della guida autonoma e di come stiamo cercando di risolverla con un pizzico di intelligenza artificiale (IA) e qualche idea innovativa. Sapete, quando pensiamo alle auto che si guidano da sole, la sicurezza e il comfort sono le prime cose che ci vengono in mente, giusto? E una parte fondamentale di questa sicurezza è la capacità dell’auto di “vedere” e capire la strada che ha davanti, specialmente quando le condizioni non sono ideali.
La Sfida: Vedere la Strada in Ogni Condizione
Immaginate di guidare di notte, magari sotto la pioggia battente o sulla neve. La visibilità è ridotta, l’asfalto riflette le luci in modo strano, e capire se la strada è semplicemente bagnata, ghiacciata o coperta di neve diventa difficile persino per noi umani. Ora pensate a un’auto a guida autonoma: per lei, questa sfida è ancora più grande! Riconoscere correttamente le condizioni del manto stradale – asciutto, bagnato, innevato – è cruciale. Perché? Perché da questo dipende la distanza di frenata, la velocità da mantenere, e in generale la capacità dell’auto di reagire prontamente e in sicurezza. Un errore qui può fare la differenza.
Molti incidenti, purtroppo, avvengono proprio quando l’asfalto non è asciutto. La ridotta aderenza aumenta pericolosamente lo spazio necessario per fermarsi. Ecco perché un sistema che identifica con precisione le condizioni della strada può letteralmente salvare vite, permettendo all’auto di adattare la sua guida in tempo reale.
Negli anni sono state proposte diverse soluzioni. Alcuni metodi tradizionali usano sensori specifici, analisi della polarizzazione della luce riflessa, o raggi infrarossi. Altri si sono affidati al machine learning classico, come le Support Vector Machines (SVM), raggiungendo buone precisioni (intorno al 90%), ma forse non ancora abbastanza per la sicurezza totale richiesta dalla guida autonoma. Poi è arrivato il deep learning, in particolare le reti neurali convoluzionali (CNN), che sono bravissime ad analizzare immagini e riconoscere pattern spaziali. Modelli come VGG, ResNet, ConvNeXt hanno dato una bella spinta, ma restano delle sfide, soprattutto con immagini di bassa qualità (pensate alle riprese notturne, piene di rumore e con poca luce) e spesso questi modelli mancano un po’ di “interpretabilità”, cioè non è sempre chiaro *come* arrivino a una certa conclusione.
La Nostra Idea: IQEFD – Migliorare la Vista e Imparare Meglio
Ed è qui che entriamo in gioco noi con la nostra proposta, che abbiamo chiamato IQEFD (Image Quality Enhancement and Feature Distillation). L’idea di base è semplice ma potente: e se potessimo prima “migliorare” la qualità delle immagini che l’IA vede, soprattutto quelle notturne, e poi usare questa versione migliorata per “insegnare” all’IA principale a riconoscere meglio le condizioni stradali anche dalle immagini originali, magari più scure o rumorose?
Come Funziona il Nostro IQEFD?
Vi spiego i passaggi chiave del nostro sistema:
- Preprocessing: Prepariamo le immagini, ridimensionandole tutte a 224×224 pixel e applicando un’equalizzazione dell’istogramma per un primo miglioramento del contrasto.
- Migliorare la Vista (Image Enhancement): Usiamo una rete neurale leggera ed efficiente chiamata Zero-DCE. Questa rete è specializzata nel migliorare immagini a bassa luminosità. In pratica, prende un’immagine scura e la “illumina” in modo intelligente, rendendo visibili dettagli che prima erano nascosti nell’ombra. Questo ci dà una versione “enhanced” (migliorata) di ogni immagine.
- Estrarre le Caratteristiche (Feature Extraction): Usiamo una potente rete neurale chiamata ConvNeXt come “spina dorsale” (backbone). Ne usiamo due versioni identiche ma con scopi diversi: una (ConvNeXt-1) analizza l’immagine originale per estrarre le caratteristiche di base, l’altra (ConvNeXt-2) analizza l’immagine migliorata da Zero-DCE per estrarre quelle che chiamiamo “caratteristiche migliorate”.
- Capire i Dettagli (Feature Refinement e Fusion): Le caratteristiche estratte da ConvNeXt-1 non bastano. Le passiamo attraverso un nostro modulo speciale, il Bidirectional Fusion Module. Questo modulo è furbo: combina informazioni prese a diverse “scale” (come guardare l’immagine da vicino e da lontano contemporaneamente) per non perdere dettagli importanti. Dentro questo modulo c’è anche il nostro Hybrid Attention Mechanism (HAM). L’HAM è come un evidenziatore: aiuta la rete a concentrarsi sulle aree più importanti dell’immagine (il manto stradale!) e sui canali di informazione più rilevanti, ignorando il rumore o le parti inutili. Le caratteristiche così “raffinate” vengono poi fuse con le “caratteristiche migliorate” (quelle dall’immagine luminosa) per ottenere delle “caratteristiche fuse attentive”.
- Il Segreto: Distillazione della Conoscenza dei Materiali (Feature Distillation): Qui sta il cuore della nostra innovazione! Usiamo le “caratteristiche migliorate” (estratte dall’immagine resa più chiara da Zero-DCE) come un “insegnante” (teacher). Questo insegnante guida l’apprendimento delle “caratteristiche fuse attentive” (lo “studente” – student). In pratica, l’insegnante trasferisce la sua conoscenza più ricca, derivata dall’immagine di qualità superiore, allo studente che sta lavorando sull’immagine originale. Questo processo, chiamato feature distillation, aiuta lo studente a imparare a riconoscere le proprietà dei materiali (asciutto, bagnato, neve) in modo molto più robusto, anche quando l’immagine di partenza non è perfetta. Stiamo trasferendo una “conoscenza migliorata dei materiali”.
- La Decisione Finale (Identification): Le “caratteristiche fuse attentive”, ora arricchite dalla conoscenza distillata, vengono date a un classificatore finale (un semplice strato fully connected con funzione Softmax) che decide: la strada è asciutta, bagnata o innevata? Usiamo anche una tecnica chiamata Focal Loss per gestire meglio eventuali squilibri nel numero di immagini per categoria e concentrarci sugli esempi più difficili da classificare.

Alla Prova dei Fatti: I Risultati
Abbiamo messo alla prova il nostro IQEFD su due dataset pubblici creati appositamente per questo compito, derivati da video YouTube: uno con immagini notturne girate in aree urbane con illuminazione ambientale (YouTube-w-ALI) e uno con immagini notturne da strade extraurbane o autostrade, senza illuminazione ambientale (YouTube-w/o-ALI), quest’ultimo particolarmente difficile.
I risultati sono stati davvero incoraggianti! Su YouTube-w-ALI abbiamo raggiunto un’accuratezza del 98.04%, mentre sul più ostico YouTube-w/o-ALI siamo arrivati al 98.68%. Questi numeri superano quelli dei modelli precedenti, incluso l’ultimo stato dell’arte (MBFN). La cosa notevole è che IQEFD sembra cavarsela particolarmente bene proprio nelle condizioni di buio e bassa qualità, dimostrando la sua robustezza.

Ma non ci siamo fermati qui. Volevamo vedere se la nostra idea fosse valida anche al di fuori delle strade. Abbiamo testato IQEFD su un dataset classico di classificazione di materiali chiamato MattrSet (con immagini di borse e scarpe fatte di materiali come poliuretano, tela, nylon, poliestere). Anche qui, IQEFD ha mostrato una buona capacità di generalizzazione, ottenendo un’accuratezza media del 75.86%, superando altri modelli specifici per materiali. Questo suggerisce che il nostro approccio ha un potenziale più ampio.
Robustezza a Prova di Bomba
Un buon modello non deve solo essere accurato, ma anche robusto. Lo abbiamo messo sotto stress in due modi:
- Test Black-Box con Rumore: Abbiamo aggiunto rumore casuale (Gaussiano e SaleePepe) a una parte delle immagini di test, simulando disturbi del sensore o errori di trasmissione. IQEFD ha mantenuto alte prestazioni, dimostrando di non aver semplicemente “imparato a memoria” i dati ma di aver colto caratteristiche robuste.
- Test White-Box con Attacchi Avversari: Abbiamo usato una tecnica chiamata FGSM per creare “immagini trabocchetto” appositamente studiate per ingannare l’IA. Anche in questo caso, IQEFD si è dimostrato resistente, mantenendo un’elevata accuratezza.
Questi test confermano che il nostro modello è solido e affidabile anche in condizioni non perfette o di fronte a tentativi di “sabotaggio”.
Velocità e Praticità
Ovviamente, per la guida autonoma, la velocità è essenziale. Abbiamo misurato le prestazioni di IQEFD in termini di frame rate (immagini elaborate al secondo) e latenza (tempo di risposta). I risultati mostrano che il nostro modello è abbastanza veloce per applicazioni in tempo reale, permettendo al sistema di prendere decisioni rapide e sicure.
Guardando Dentro l’IA: Cosa Abbiamo Imparato?
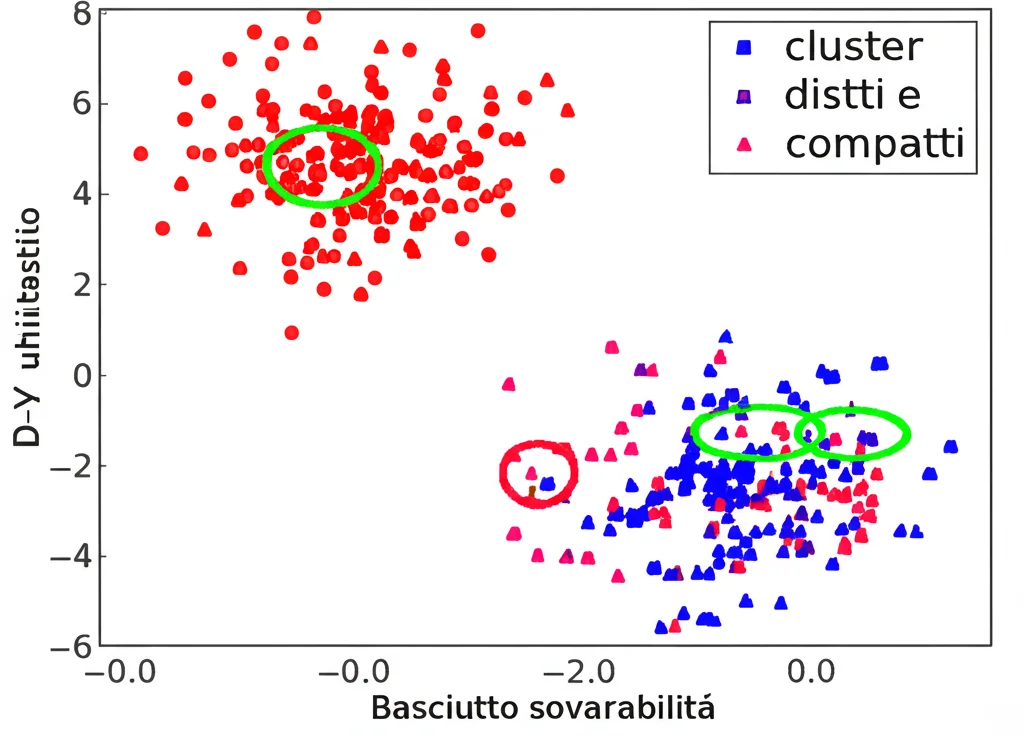
Abbiamo anche cercato di capire *come* ragiona il nostro modello. Usando tecniche di visualizzazione come t-SNE e Grad-CAM, abbiamo potuto vedere che le caratteristiche estratte da IQEFD separano molto bene le diverse condizioni stradali (i “cluster” sono ben definiti) rispetto ad altri modelli. Le mappe di calore di Grad-CAM mostrano che IQEFD si concentra correttamente sulle regioni importanti della strada, ignorando le distrazioni. Questo non solo conferma che funziona bene, ma aumenta anche la nostra fiducia nel suo processo decisionale. Le analisi di ablazione (togliendo pezzi del modello per vedere quanto contribuiscono) hanno confermato che ogni componente, specialmente il miglioramento dell’immagine con Zero-DCE e la distillazione delle caratteristiche, gioca un ruolo cruciale nel successo finale.
Conclusioni e Prossimi Passi
In sintesi, abbiamo sviluppato IQEFD, un nuovo approccio per l’identificazione delle condizioni del manto stradale che sfrutta l’idea innovativa di trasferire conoscenza da immagini migliorate a quelle originali tramite feature distillation. Questo metodo si è dimostrato molto efficace e robusto, specialmente in condizioni di scarsa illuminazione notturna, superando i modelli precedenti.
Crediamo che questa idea di “trasferire conoscenza migliorata dei materiali” apra nuove prospettive interessanti non solo per la guida autonoma ma anche per altri compiti di visione artificiale dove la qualità dell’immagine è una sfida. Certo, c’è sempre spazio per migliorare. In futuro, potremmo esplorare come integrare informazioni specifiche sulla texture o magari combinare dati visivi con altre modalità, come descrizioni testuali, per rendere l’identificazione ancora più precisa e completa.
Il viaggio verso una guida autonoma completamente sicura è ancora lungo, ma speriamo che il nostro lavoro con IQEFD rappresenti un piccolo ma significativo passo avanti!
Fonte: Springer





