
FunDa: L’Analisi Dati Serverless Scalabile e le Query In Situ Diventano Realtà!
Amici appassionati di dati e tecnologia, mettetevi comodi! Oggi voglio parlarvi di una sfida che, ne sono certo, molti di voi avranno incontrato: come gestire analisi dati complesse e query pesanti senza impazzire dietro a infrastrutture costose e poco flessibili? Beh, nel mondo del cloud computing, il modello “serverless” sembrava la risposta magica: paghi solo per quello che usi, niente server da gestire… un sogno! Ma, come spesso accade, la realtà ha presentato qualche intoppo, specialmente per chi, come noi, lavora con carichi di lavoro analitici che durano nel tempo e richiedono parecchie risorse.
Il serverless tradizionale, con la sua filosofia “Function-as-a-Service” (FaaS), è fantastico per compiti brevi, effimeri. Ma quando si tratta di interrogare montagne di dati “in situ” (cioè, direttamente dove si trovano, senza spostarli) o di lanciare algoritmi di machine learning che macinano numeri per ore, beh, lì iniziano i dolori. Limiti di tempo di esecuzione, poca memoria, difficoltà di comunicazione tra funzioni e, non da ultimo, costi che possono lievitare inaspettatamente. Insomma, per l’analisi dati “seria”, il serverless classico mostrava un po’ la corda.
La Nostra Risposta: Vi Presento FunDa!
Proprio per superare questi ostacoli, abbiamo tirato fuori dal cilindro FunDa. Immaginatelo come un framework di analisi dati serverless pensato per funzionare sia nei vostri data center (on-premises), magari sfruttando quelle macchine del laboratorio universitario che spesso restano inutilizzate, sia su cloud pubblici come AWS. La bellezza di FunDa è che estende un nostro precedente lavoro, DaskDB, un sistema che già permetteva di fare analisi dati unificate ed eseguire query SQL direttamente sui file raw, anche quelli geospaziali, senza dover passare per il solito, noioso processo ETL (Extract, Transform, Load).
Con FunDa, abbiamo voluto portare questa potenza nel mondo serverless, ma in un modo “vero”, che supportasse sia i task veloci sia le maratone computazionali. L’idea è di darvi la flessibilità del serverless – scalabilità automatica, niente gestione di server – ma con la robustezza necessaria per l’analisi dati avanzata. E, cosa non da poco, mantenendo i vostri dati al sicuro localmente se lo desiderate, con pieno controllo su hardware e software.
Come Funziona Sotto il Cofano?
Senza entrare in dettagli troppo tecnici che potrebbero farvi sbadigliare, FunDa si basa su alcuni pilastri:
- DaskDB: come dicevo, è il nostro motore per l’analisi distribuita e le query SQL in situ. Permette di usare funzioni Python, librerie e User-Defined Functions (UDF) direttamente nelle query. Una manna dal cielo per i data scientist!
- Fn Project: è un framework serverless open-source che ci permette di creare e gestire le funzioni in modo flessibile, sia on-premises che in cloud.
- Docker: usiamo i container Docker per impacchettare FunDa e le sue dipendenze. Questo garantisce che funzioni allo stesso modo ovunque, dal vostro laptop al cluster in cloud. E con Docker Swarm, gestiamo l’orchestrazione di questi container in modo efficiente.
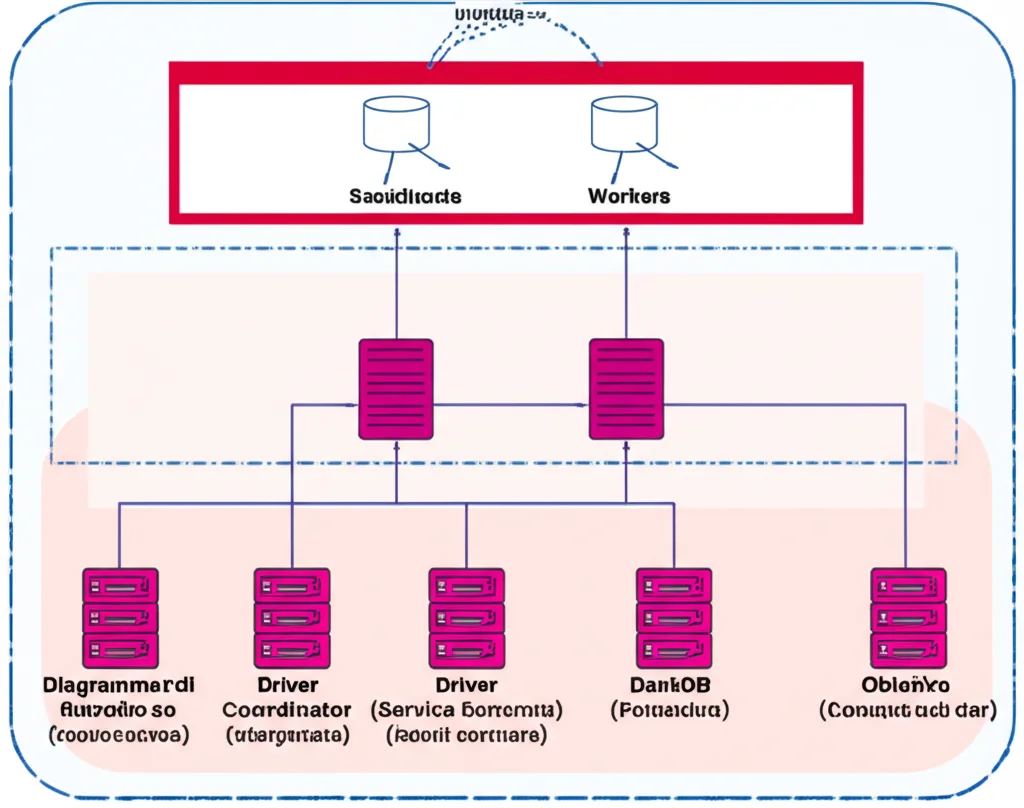
L’architettura di FunDa prevede alcuni componenti chiave:
- Un Service Coordinator che riceve i vostri “job” (query, task analitici) tramite un’interfaccia web, una chiamata HTTP o una funzione serverless dedicata, e li mette in coda.
- Un Driver che orchestra l’esecuzione, creando, avviando e fermando i container necessari (Scheduler e Worker di DaskDB) sulle macchine disponibili.
- Lo Scheduler di DaskDB, che una volta attivato dal Driver, coordina la distribuzione dei sotto-task ai vari Worker.
- I Worker di DaskDB, che eseguono materialmente i calcoli in parallelo. Il Driver li fa partire quando serve e li spegne a lavoro finito, liberando completamente le risorse.
Questo sistema ci permette di usare dinamicamente le risorse: se avete un piccolo job, FunDa userà poche macchine; se il carico aumenta, ne attiverà di più. E quando tutto è finito, le macchine tornano disponibili per altri usi. Pensate ai laboratori universitari: le macchine possono essere usate per FunDa quando sono libere, senza interferire con le normali attività.
Affrontare il Tallone d’Achille: il “Cold Start”
Uno dei problemi più sentiti nel mondo serverless è il cosiddetto “cold start”. Quando una funzione non viene usata per un po’, il sistema la “spegne” per risparmiare risorse. Alla successiva chiamata, deve essere reinizializzata da zero, causando un ritardo (latency) che può essere fastidioso, specialmente per applicazioni che richiedono risposte rapide. Immaginate di dover caricare modelli di machine learning e dataset ogni volta: un’eternità!
Nel nostro prototipo iniziale, che abbiamo chiamato retroattivamente FunDaprelim, avevamo identificato proprio il cold start come un collo di bottiglia. I container Docker erano un po’ pesantucci e questo influiva sui tempi di avvio. Con FunDa, ci siamo rimboccati le maniche e abbiamo lavorato sodo per mitigare questo problema:
- Ottimizzazione delle Immagini Docker: Siamo passati da immagini Ubuntu standard a una versione “slim” di Debian 12 (Bookworm). Abbiamo curato maniacalmente i pacchetti installati, includendo solo lo stretto indispensabile. Risultato? Immagini Docker significativamente più piccole (ad esempio, lo Scheduler è passato da 6.9GB a circa 1.8GB!) e quindi più veloci da avviare.
- Versione di Python: Abbiamo adottato Python 3.12, che offre un bel boost di prestazioni rispetto alle versioni precedenti.
- Scheduler Sempre Attivo e Pre-caricamento: Invece di avviare e fermare lo Scheduler di DaskDB per ogni job, lo teniamo sempre attivo. Inoltre, pre-carichiamo le librerie essenziali (come la JVM per Calcite, l’interprete Python, ecc.). Così, quando arriva una query, il sistema è già pronto a scattare.
- Caching Intelligente: FunDa, grazie a DaskDB, sfrutta il caching di Dask per i risultati intermedi costosi da calcolare e usati frequentemente. Abbiamo anche implementato un caching dei metadati dei file: se analizzate più volte lo stesso dataset, FunDa ricorda informazioni come il numero di righe, evitando di ricalcolarle.
Queste ottimizzazioni hanno ridotto drasticamente la latenza di cold start, rendendo FunDa molto più reattivo.
Interfacce Semplici per Tutti
Abbiamo pensato anche a come interagire con FunDa. Potete sottomettere i vostri job in tre modi:
- Tramite una funzione serverless: Create la vostra funzione (in Python, Java, Go…) usando il framework Fn project, inseriteci dentro il codice DaskDB e voilà!
- Tramite un’interfaccia Web: C’è una comoda pagina web (protetta da password) dove potete caricare i vostri script DaskDB e vedere i risultati direttamente nel browser.
- Tramite richieste HTTP dirette: Per gli amanti del terminale, potete inviare i job con un semplice comando `curl` o simili.
Per gli amministratori di sistema, ci sono API per gestire i worker, avviarli, fermarli, e così via.
FunDa alla Prova dei Fatti: I Benchmark
Parole, parole, parole… ma i numeri? Abbiamo messo FunDa sotto torchio con una serie di benchmark standard (TPC-H, TPC-DS), un benchmark custom con User-Defined Functions (regressione lineare e K-Means), query geospaziali sul dataset GeoNB, e persino il dataset NYC Taxi e Limousine Commission usato da altri sistemi come Flint. Abbiamo testato FunDa sia su un nostro cluster locale (4 nodi con CPU i5 e 8GB di RAM) sia su piccole istanze AWS (t2.micro, per dimostrare che gira anche con risorse limitate).
I risultati? Beh, sono stati entusiasmanti! Rispetto al nostro prototipo FunDaprelim, FunDa ha mostrato tempi di esecuzione quasi dimezzati, soprattutto grazie alla drastica riduzione dei tempi di avvio e pre-processing. Ad esempio, su TPC-H con Scale Factor 10, una query che prima richiedeva circa 261 secondi, con FunDa ne impiega circa 155. E questo miglioramento si è visto su tutta la linea.
Anche sui task UDF, come il K-Means, abbiamo visto miglioramenti simili, con tempi totali che scendono, ad esempio, da 269 a 141 secondi. Quando abbiamo testato FunDa su AWS con TPC-DS, nonostante le risorse limitate delle istanze t2.micro, il sistema ha funzionato a dovere, dimostrando la sua flessibilità.
Efficienza dei Costi: FunDa vs. Il Resto del Mondo
Una delle cose più interessanti è stata confrontare FunDa con altri sistemi come Flint, PySpark e Spark, usando il dataset NYC Taxi. Non solo in termini di tempo, ma anche di efficienza dei costi. Abbiamo sviluppato una metrica che considera le risorse computazionali (CPU, RAM) e il costo finanziario (basato sui prezzi AWS) per unità di dati processati.
I risultati sono stati chiari: FunDa si è dimostrato significativamente più efficiente. Ad esempio, per una delle query (NT1), il “costo” per unità di dati processati da FunDa su AWS è stato di 20.17, mentre per PySpark era 63.64 e per Flint 44.89. Questo dimostra che FunDa non solo è performante, ma sa anche come farvi risparmiare, adattandosi bene anche alle configurazioni cloud.
Molti framework serverless si appoggiano ad AWS Lambda che, sebbene popolare, può diventare costoso per carichi di lavoro intensi. FunDa, invece, può usare istanze EC2 standard, che in scenari di alta utilizzazione possono essere fino al 50% più economiche. Pensate a un’università: potrebbe usare FunDa su una singola istanza EC2 per far lavorare gli studenti in modalità serverless, risparmiando un bel po’ rispetto a Lambda e scalando aggiungendo altre istanze EC2 se necessario.
Perché FunDa Potrebbe Essere la Svolta?
Crediamo che FunDa porti diversi vantaggi:
- Flessibilità: Gira on-premises o in cloud, su hardware modesto o su cluster potenti.
- Controllo: Se usato on-premises, avete pieno controllo su dati, hardware e software.
- Costi Ridotti: Sfruttando hardware esistente o istanze EC2 più economiche di Lambda, si può risparmiare.
- Supporto per Task Complessi: Niente limiti di tempo stringenti come nelle FaaS tradizionali, ideale per analisi dati che richiedono tempo.
- Open Source: È una piattaforma aperta, che speriamo possa far avanzare la ricerca nell’analisi dati serverless.
- Facilità d’Uso: Grazie a DaskDB, integrare UDF Python esistenti è un gioco da ragazzi, senza dover riscrivere codice per adattarlo ad API specifiche come quelle di Spark.
A differenza di molti sistemi legati a doppio filo ad AWS Lambda, FunDa è stato pensato per essere modulare. Sebbene ora usi DaskDB, la sua architettura potrebbe essere adattata per funzionare con altri motori di elaborazione distribuita come Spark o Ray.

Cosa Ci Riserva il Futuro?
Siamo molto soddisfatti dei risultati, ma non ci fermiamo qui. Stiamo già pensando a come migliorare ulteriormente FunDa. Tra le idee:
- Integrazione con storage ad alte prestazioni come Apache Crail, per ridurre i colli di bottiglia I/O.
- Sfruttare il nuovo compilatore JIT (Just-In-Time) di Python (dalla versione 3.13) per accelerare ulteriormente i calcoli.
- Ottimizzare l’esecuzione su cloud privati e ibridi, ad esempio con partizionamento dei dati e caching adattivo specifici per S3 quando si usa AWS.
Insomma, FunDa è il nostro tentativo di rendere l’analisi dati serverless una soluzione pratica, efficiente e accessibile per tutti quei task complessi che finora faticavano a trovare una casa nel mondo serverless. Speriamo che questo viaggio nel cuore di FunDa vi abbia incuriosito e, perché no, ispirato a esplorare nuove frontiere nell’analisi dei vostri dati!
Fonte: Springer





