Farmaci Intelligenti per il Colon: La Magia della Chemiometria e del Machine Learning
Ciao a tutti! Oggi voglio portarvi con me in un viaggio affascinante nel mondo della farmaceutica avanzata, un campo dove scienza e tecnologia si incontrano per creare soluzioni quasi futuristiche. Parliamo di un problema specifico ma molto importante: come far arrivare un farmaco esattamente dove serve, ad esempio nel colon, superando le insidie del nostro sistema digestivo, come l’ambiente acido dello stomaco? È una bella sfida, vero? Soprattutto per trattare malattie come quelle infiammatorie intestinali.
Una delle strategie più promettenti è quella di “vestire” il farmaco, nel nostro caso l’acido 5-aminosalicilico (5-ASA), un principio attivo comune per queste patologie, con un rivestimento speciale fatto di polisaccaridi. Questi zuccheri complessi sono furbi: resistono all’ambiente dello stomaco e dell’intestino tenue, ma una volta arrivati nel colon, i batteri “buoni” che vivono lì li “mangiano”, liberando finalmente il farmaco proprio dove deve agire. Geniale, no?
Però, c’è un “ma”. Come facciamo a sapere esattamente *quando* e *quanto* farmaco verrà rilasciato? Dipende da tanti fattori: il tipo di polisaccaride usato, le condizioni specifiche dell’intestino (che possono variare!). Provare e riprovare in laboratorio richiede tempo e risorse. Ed è qui che entra in gioco la magia della tecnologia!
La Potenza della Luce e dei Dati: Raman e Machine Learning
Abbiamo pensato: e se potessimo *prevedere* il rilascio del farmaco usando strumenti computazionali avanzati? Per farlo, abbiamo combinato due tecniche potentissime: la spettroscopia Raman e il machine learning (ML).
La spettroscopia Raman è una tecnica incredibile: usando un raggio laser, possiamo ottenere una sorta di “impronta digitale” molecolare del nostro campione (la formulazione farmaceutica). Questa impronta ci dice tantissimo sulla composizione e sulla struttura del materiale, anche su come cambiano nel tempo. È super sensibile e precisa, perfetta per analizzare le nostre formulazioni rivestite.
Abbiamo quindi raccolto un bel po’ di questi dati spettrali Raman (pensate a grafici complessi con tantissime informazioni) in diverse condizioni e a diversi tempi di rilascio del nostro 5-ASA. Ma come interpretare questa montagna di dati? Qui scende in campo il machine learning. L’idea è “insegnare” a un computer a riconoscere i pattern nascosti in questi spettri e a collegarli alla quantità di farmaco rilasciato. In pratica, creiamo un modello predittivo che, guardando lo spettro Raman, ci dice come si comporterà il farmaco.
Domare la Bestia dei Dati: Preprocessing Essenziale
Prima di dare i dati in pasto ai nostri modelli di ML, però, dovevamo metterli un po’ in ordine. Immaginate di avere 155 campioni, e per ognuno più di 1500 caratteristiche spettrali, più altre informazioni come il tempo, il tipo di “ambiente” (simulando quello di pazienti, ratti, cani o un controllo) e il tipo di polisaccaride usato. Un bel caos!
Quindi, abbiamo fatto un po’ di “pulizia” e preparazione, il cosiddetto preprocessing:
- Normalizzazione: Abbiamo messo tutti i dati sulla stessa scala, per evitare che alcune caratteristiche “urlassero” più forte di altre solo perché avevano valori numerici più grandi.
- Analisi delle Componenti Principali (PCA): Con così tante caratteristiche spettrali, c’era il rischio di confondere i modelli o di renderli troppo lenti. La PCA ci ha aiutato a ridurre la dimensionalità, cioè a “riassumere” le informazioni più importanti in un numero minore di “super-caratteristiche”, senza perdere l’essenziale. È come fare un riassunto molto efficace di un libro lunghissimo!
- Rilevamento Outlier: Abbiamo cercato e gestito i dati “strani” o anomali (outlier) usando la Distanza di Cook. Questi dati potrebbero distorcere i risultati, quindi è meglio individuarli e trattarli con cautela.
Con i dati belli puliti e ordinati, eravamo pronti per la fase successiva: l’addestramento dei modelli.

I Campioni in Gara: EN, GRR e MLP
Abbiamo messo alla prova tre diversi modelli di machine learning, ognuno con i suoi punti di forza:
- Elastic Net (EN): Un modello che è un mix intelligente tra due tecniche popolari (LASSO e Ridge). È bravo a selezionare le caratteristiche più importanti e a gestire dati dove le variabili sono correlate tra loro.
- Group Ridge Regression (GRR): Una variante della Ridge Regression pensata per quando i dati hanno una struttura a gruppi (ad esempio, diverse categorie dello stesso tipo). Applica la regolarizzazione a livello di gruppo.
- Multilayer Perceptron (MLP): Questo è un tipo di rete neurale artificiale, un modello di deep learning. Immaginatelo come un “cervello” artificiale con strati di neuroni interconnessi, capace di imparare pattern molto complessi e non lineari. È particolarmente potente con dati ad alta dimensionalità come i nostri spettri.
Quale di questi sarebbe stato il migliore nel prevedere il rilascio del nostro 5-ASA? La sfida era aperta!
L’Ingrediente Segreto: Ottimizzazione con l’Algoritmo della Muffa Mucillaginosa
Un modello di machine learning ha tanti “pulsanti” da regolare, i cosiddetti iperparametri. Trovare la combinazione perfetta di questi settaggi è cruciale per ottenere le massime prestazioni. Farlo a mano sarebbe un incubo.
Per questo, abbiamo usato un aiutante davvero particolare: lo Slime Mould Algorithm (SMA). Sì, avete letto bene! È un algoritmo di ottimizzazione ispirato al comportamento affascinante delle muffe mucillaginose (slime moulds), organismi unicellulari che sono incredibilmente bravi a trovare il cibo (cioè la soluzione ottimale a un problema) esplorando l’ambiente in modo efficiente. L’SMA ci ha aiutato a trovare i migliori iperparametri per ciascuno dei nostri tre modelli (EN, GRR, MLP) in modo automatico ed efficace.
Il Momento della Verità: I Risultati!
Dopo aver preparato i dati, scelto i modelli e ottimizzato i loro parametri, è arrivato il momento di vedere chi aveva vinto la sfida. Abbiamo addestrato i modelli su una parte dei dati (l’80%) e li abbiamo testati sulla parte rimanente (il 20%), quella che non avevano mai visto prima. Per essere sicuri dei risultati, abbiamo usato anche una tecnica chiamata cross-validation (con k=3), che in pratica ripete il test su diverse suddivisioni dei dati per garantire che le prestazioni non siano dovute al caso.
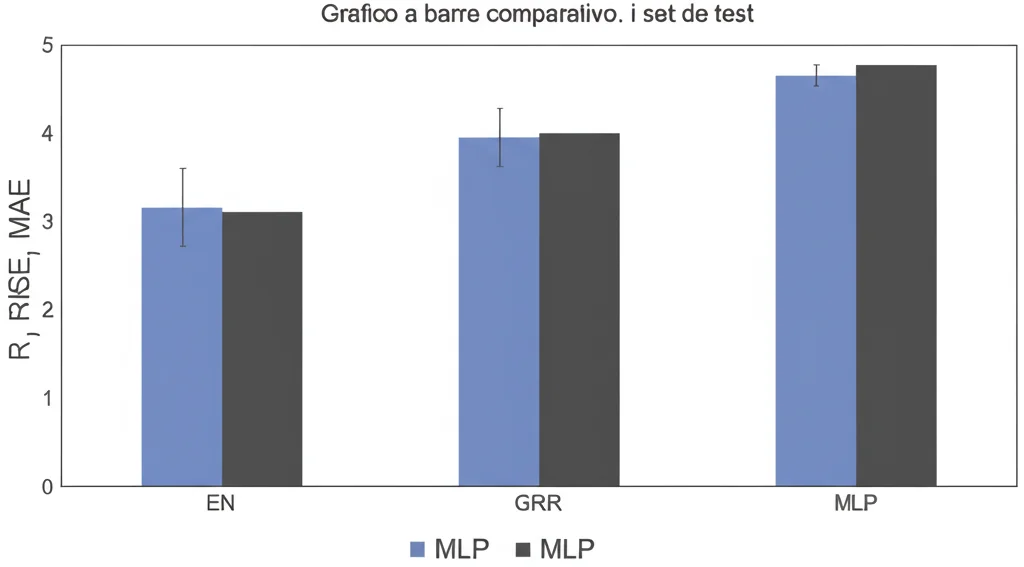
E i risultati sono stati… chiari! Abbiamo usato diverse metriche per valutare le prestazioni:
- Coefficiente di Determinazione (R²): Misura quanto bene il modello “spiega” la variabilità dei dati. Un valore vicino a 1 è ottimo.
- Root Mean Square Error (RMSE): L’errore quadratico medio, indica quanto si sbagliano in media le previsioni (più basso è, meglio è).
- Mean Absolute Error (MAE): L’errore assoluto medio, simile all’RMSE ma meno sensibile agli errori grandi (anche qui, più basso è, meglio è).
Beh, signore e signori, il Multilayer Perceptron (MLP) ha letteralmente stracciato la concorrenza!
Sul set di test, l’MLP ha raggiunto un R² di 0.9989 (praticamente perfetto!), mentre l’EN si è fermato a 0.9760 (comunque buono) e il GRR molto più indietro con 0.7137. Anche guardando gli errori, l’MLP ha mostrato valori incredibilmente bassi: RMSE di 0.0084 e MAE di 0.0067, molto inferiori a quelli di EN (RMSE 0.0342, MAE 0.0267) e GRR (RMSE 0.0907, MAE 0.0744).
Visualizzare il Successo: Grafici che Parlano
Non ci siamo fidati solo dei numeri. Abbiamo anche creato dei grafici, come i parity plot, che confrontano i valori reali del rilascio del farmaco con quelli previsti dai modelli. Nel grafico dell’MLP, i punti si allineavano quasi perfettamente sulla diagonale, confermando visivamente la sua straordinaria accuratezza. I grafici di EN e GRR mostravano una dispersione maggiore.
Inoltre, abbiamo analizzato la learning curve (curva di apprendimento) dell’MLP. Questo grafico ci mostra come il modello impara durante l’addestramento. La curva dell’MLP era bellissima: mostrava che il modello imparava in modo efficiente senza “imparare a memoria” i dati di training (un problema chiamato overfitting), il che significa che è bravo a generalizzare e fare previsioni su dati nuovi.
Cosa Significa Tutto Questo?
Questa ricerca dimostra che combinare la spettroscopia Raman con modelli avanzati di machine learning, in particolare le reti neurali MLP, e un’attenta preparazione dei dati, è un approccio potentissimo per prevedere il rilascio di farmaci da formulazioni complesse come quelle rivestite con polisaccaridi per il delivery colonico.
Perché è importante? Perché ci permette di:
- Accelerare lo sviluppo: Possiamo testare virtualmente molte più formulazioni e condizioni in meno tempo e con costi ridotti rispetto ai soli esperimenti di laboratorio.
- Ottimizzare le terapie: Possiamo progettare rivestimenti che rilascino il farmaco in modo più preciso e personalizzato.
- Migliorare l’efficacia dei trattamenti: Assicurare che il farmaco arrivi nel posto giusto al momento giusto è fondamentale per curare malattie come quelle del colon.
Il modello MLP si è rivelato uno strumento robusto e affidabile per questo compito. Ovviamente, la ricerca non si ferma qui. Potremmo esplorare architetture di reti neurali ancora più sofisticate, usare dataset più grandi o provare nuove tecniche di ottimizzazione.
Ma per ora, possiamo dire di avere uno strumento in più, potente e preciso, per progettare la prossima generazione di farmaci intelligenti destinati al nostro colon. È un passo avanti entusiasmante che unisce chimica, fisica, biologia e intelligenza artificiale per la nostra salute!
Fonte: Springer