
Deep Learning e Percorsi di Vita: Svelare il Futuro della Salute tra Potenzialità e Illusioni
Ciao a tutti! Oggi voglio portarvi con me in un’avventura affascinante nel mondo dei dati, della salute e dell’intelligenza artificiale. Parleremo di come le nostre vite, fin dall’infanzia, lascino tracce che possono predire la nostra salute futura e di come strumenti potentissimi come il Deep Learning (DL) e l’Intelligenza Artificiale Spiegabile (XAI) stiano cercando di decifrare questi complessi percorsi.
Capire le Trame della Vita: Una Sfida Complessa
Immaginate la vita di una persona come un lungo filo intrecciato. Ogni evento, ogni esperienza – dalle difficoltà vissute da bambini (le cosiddette adverse childhood experiences o ACEs) ai fattori ambientali, all’istruzione, al lavoro – aggiunge un colore, una torsione a quel filo. L’epidemiologia del corso della vita cerca proprio di capire come questi intrecci, che si sviluppano nel tempo, influenzino il rischio di ammalarci più avanti negli anni. Ad esempio, sappiamo che traumi infantili o povertà possono aumentare il rischio di malattie croniche da adulti, ma l’impatto dipende da quando accadono, da quanto sono intensi e da come si combinano con altre esperienze.
Grazie ai registri sanitari nazionali e ad altri grandi database, oggi abbiamo accesso a una quantità enorme di dati longitudinali, che seguono le persone per lunghi periodi. Un’opportunità incredibile! Ma c’è un “ma”. I metodi tradizionali che usiamo in epidemiologia, come i modelli di regressione o i punteggi di rischio, fanno fatica. Spesso semplificano troppo, assumendo relazioni lineari e ignorando le sfumature temporali e le differenze individuali. È come cercare di capire una sinfonia ascoltando solo poche note isolate.
Entra in Scena il Deep Learning: Un Nuovo Orizzonte?
Qui entra in gioco il Deep Learning. Questi modelli di intelligenza artificiale, ispirati al funzionamento del cervello umano, sono bravissimi a scovare pattern complessi e relazioni non lineari direttamente dai dati, senza che dobbiamo dirgli noi cosa cercare. Pensate a reti neurali ricorrenti (RNN) o convoluzionali (CNN): sono architetture nate per gestire dati sequenziali o temporali, come le nostre storie di vita registrate nei dati sanitari elettronici (EHR).
Il potenziale è enorme: potremmo migliorare le previsioni di rischio individuali, scoprire nuovi fattori di rischio nascosti, identificare quei “periodi sensibili” nella vita in cui un intervento di salute pubblica potrebbe essere più efficace. Sembra fantastico, vero? Però, calma. Siamo ancora agli inizi, soprattutto nell’applicare questi metodi specificamente all’analisi del corso della vita. Funzioneranno davvero bene con dati che sono spesso “sparsi”, cioè con informazioni mancanti o eventi rari registrati in modo irregolare nel tempo? E quale modello DL scegliere tra i tanti disponibili (come MLSTM-FCN, LSTMAttention, ResNet, InceptionTime)?
Il Dilemma della “Scatola Nera” e la Promessa dell’IA Spiegabile (XAI)
Un altro grosso scoglio è l’interpretabilità. I modelli DL sono spesso delle “scatole nere”: funzionano benissimo nel fare previsioni, ma capire perché arrivano a una certa conclusione è difficile. E in sanità pubblica, capire il “perché” è fondamentale. Non ci basta sapere che una persona è a rischio, vogliamo capire quali fattori (e quando) contribuiscono a quel rischio per poter intervenire.
Qui entra in gioco l’Intelligenza Artificiale Spiegabile (XAI). Metodi come SHAP (Shapley additive explanations) sono diventati molto popolari. In pratica, cercano di “aprire” la scatola nera quantificando il contributo di ciascun fattore (esposizione, evento) alla previsione finale del modello per un singolo individuo. Sembra la soluzione perfetta per identificare i fattori di rischio chiave e i periodi critici, no? Ma anche qui, dobbiamo andarci cauti. SHAP e metodi simili ci dicono quanto un fattore sia predittivamente influente, ma questo non significa automaticamente che sia una causa. E in epidemiologia, distinguere tra correlazione (o influenza predittiva) e causalità è sacro!
Mettere alla Prova DL e XAI: Il Nostro Studio di Simulazione
Per vederci più chiaro, abbiamo deciso di fare un esperimento controllato. Abbiamo creato dei dati simulati che imitassero le caratteristiche dei dati reali del corso della vita, ma di cui conoscevamo perfettamente le regole sottostanti (i meccanismi causali!). Abbiamo generato diversi scenari basati su concetti epidemiologici noti, come:
- Periodo: L’impatto di un’esposizione dipende da un periodo specifico della vita (es. esposizioni critiche o sensibili).
- Ripetizioni (Accumulo): Il rischio aumenta con esposizioni ripetute nel tempo (es. stress cronico).
- Ordine: La sequenza temporale degli eventi è importante (es. depressione che precede un infarto).
- Tempistica: La vicinanza temporale di eventi diversi ne amplifica l’effetto.
Abbiamo poi messo alla prova diversi modelli DL (MLSTM-FCN, LSTMAttention, ResNet, InceptionTime) confrontandoli con metodi più tradizionali (regressione logistica e XGBoost, un potente modello basato su alberi decisionali) nel predire gli esiti simulati, tenendo conto anche dello squilibrio tra casi positivi e negativi (tipico dei dati sanitari). E ovviamente, abbiamo usato SHAP per vedere se le “spiegazioni” fornite dai modelli corrispondessero alle regole che avevamo inserito noi nelle simulazioni.
Cosa Abbiamo Scoperto? Sorprese e Cautele
I risultati sono stati illuminanti (e a tratti preoccupanti).
Performance Predittiva:
- I modelli DL hanno generalmente surclassato la regressione logistica e XGBoost, soprattutto quando le relazioni tra esposizioni e outcome erano complesse, dinamiche e dipendenti dal tempo. Hanno dimostrato di saper gestire meglio la “storia” contenuta nei dati.
- MA… non esiste un modello DL “re Mida” che vada bene per tutto. La performance variava a seconda dello scenario specifico. LSTMAttention andava alla grande in alcuni casi, ma inciampava in altri (come quelli basati sulla tempistica); InceptionTime brillava in altri contesti. Questo conferma che la scelta del modello deve essere fatta con cura, in base al tipo di dati e al problema.
- I modelli DL sembrano davvero cavarsela meglio con dati sparsi rispetto agli approcci tradizionali. Un punto a loro favore!
Interpretabilità con SHAP:
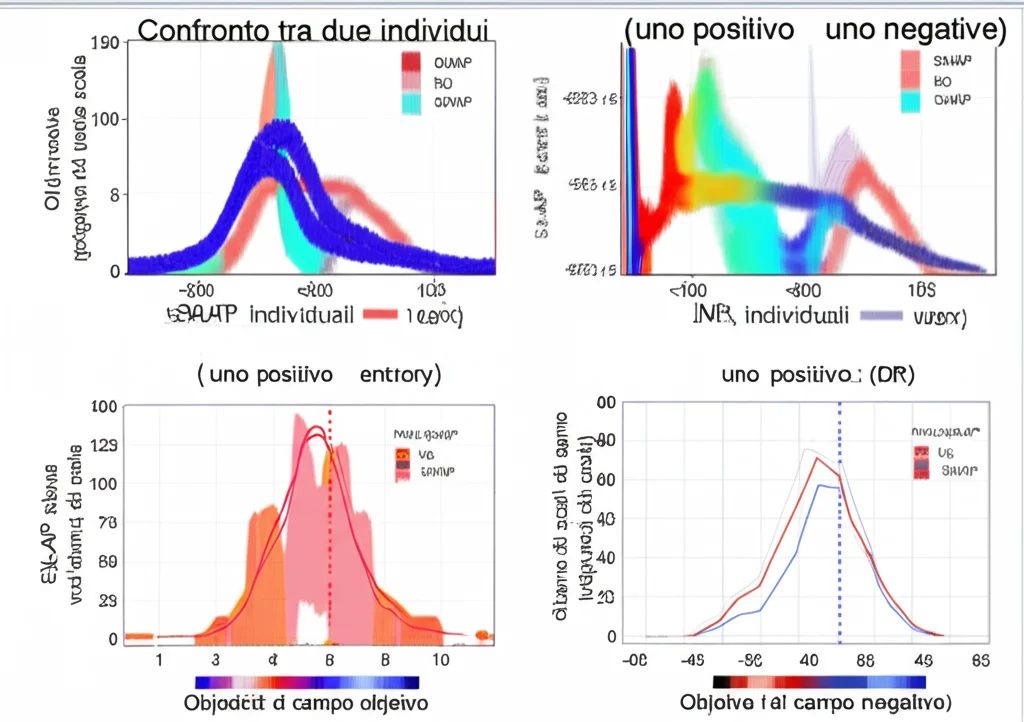
- Qui arrivano le note dolenti. Nonostante le ottime performance predittive di molti modelli, le spiegazioni fornite da SHAP spesso non corrispondevano ai veri meccanismi causali che avevamo simulato.
- SHAP identificava correttamente i fattori più influenti per la predizione, ma il modo in cui ne interpretava l’impatto (es. l’importanza di un evento in un certo momento) poteva essere fuorviante rispetto alla causa reale.
- Guardando i grafici SHAP aggregati (a livello di popolazione), era difficile, se non impossibile, capire le dinamiche temporali o causali complesse. A volte, analizzando i valori SHAP per singoli individui si poteva intuire qualcosa in più, ma non sempre e non per tutti i modelli o scenari.
- Questo è un campanello d’allarme enorme: usare SHAP (e simili) per identificare meccanismi di malattia o fattori causali può portare a conclusioni sbagliate, anche se il modello predice bene!
Le Sfide Restano: Sparsità, Costi e il Miraggio della Causalità
Il nostro studio evidenzia che, nonostante il potenziale, ci sono ancora sfide importanti. I dati del corso della vita sono spesso sparsi, e anche se i DL sembrano gestirli meglio, resta un problema. Inoltre, addestrare questi modelli richiede molte risorse computazionali.
Ma la sfida più grande, emersa chiaramente dai nostri risultati, è quella della causalità. L’epidemiologia cerca cause per prevenire malattie. I modelli DL, per ora, eccellono nella predizione basata su correlazioni complesse. Gli strumenti XAI attuali, come SHAP, non colmano questo divario in modo affidabile per i dati temporali complessi. Confondere l’influenza predittiva con la causalità è un rischio concreto che può portare a interventi di sanità pubblica inefficaci o persino dannosi.
Verso il Futuro: Potenzialità Enormi, Ma con Giudizio
Quindi, che conclusioni trarre? Il Deep Learning ha davvero il potenziale per rivoluzionare l’analisi del corso della vita e la sanità pubblica. Può aiutarci a svelare pattern nascosti nelle enormi quantità di dati che stiamo accumulando, portando a una medicina e a interventi più personalizzati e “precisi”. Immaginate poter capire molto meglio come le esperienze vissute influenzano la nostra salute a lungo termine!
Tuttavia, dobbiamo procedere con intelligenza e cautela.
- Non esiste un modello DL universale: la scelta va ponderata.
- Dobbiamo essere estremamente critici nell’interpretare le “spiegazioni” fornite dagli attuali metodi XAI come SHAP. Non sono una scorciatoia per la causalità.
- C’è un bisogno urgente di sviluppare o adattare metodi XAI che siano più in linea con i principi della causalità e che gestiscano meglio le dipendenze temporali, magari guardando a tecniche emergenti come SHAPIQ o approcci “causal-aware”.
- La trasparenza e la validazione rigorosa sono fondamentali prima di basare decisioni cliniche o politiche su questi modelli.
In sintesi, siamo di fronte a strumenti potentissimi, ma come ogni strumento potente, vanno usati con consapevolezza dei loro limiti. L’avventura dell’IA nell’esplorare i percorsi della nostra vita è appena iniziata, ed è fondamentale guidarla nella direzione giusta per migliorare davvero la salute di tutti.

Fonte: Springer





