Il Segreto del Teamwork? Ce lo Svela un Videogioco (e un po’ di Scienza!)
Avete mai pensato a come facciamo, come esseri umani (ma anche come società, o persino come cellule nel nostro corpo!), a lavorare insieme per raggiungere un obiettivo comune, specialmente quando i compiti sono complessi e ognuno ha un ruolo diverso? La divisione del lavoro e la specializzazione sono ovunque in natura, ma capirne i meccanismi profondi non è affatto semplice. Ecco, di recente mi sono imbattuto in uno studio affascinante che ha provato a svelare alcuni di questi segreti usando… un videogioco!
Un Esperimento Fuori dal Comune: Il “Gioco del Neurone Annidato”
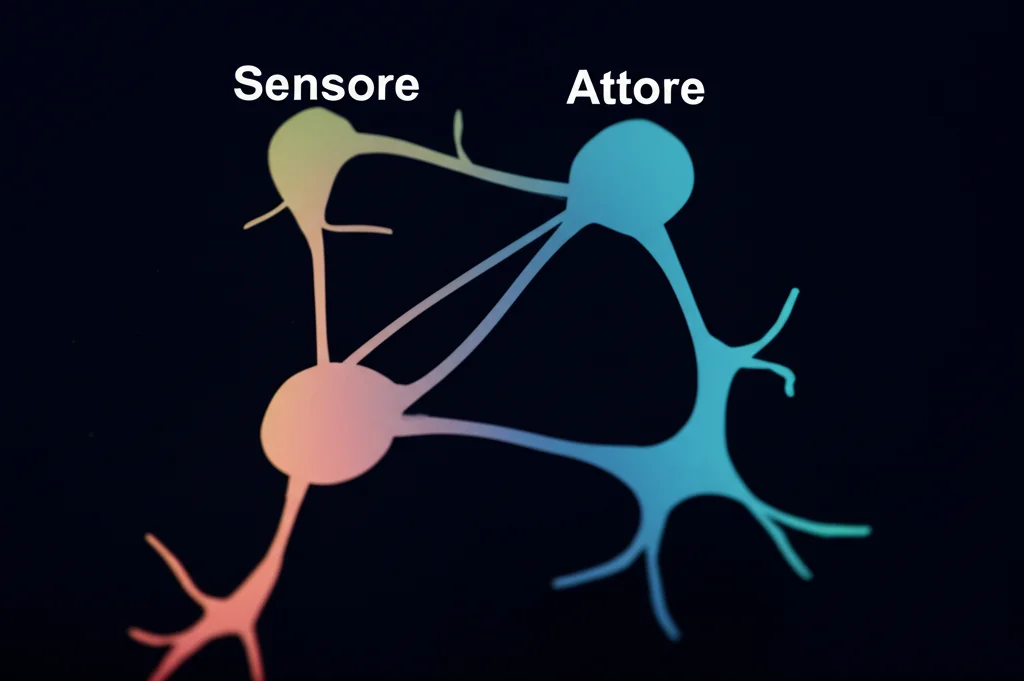
Immaginatevi questa scena: otto persone divise in due gruppi da quattro. Li chiameremo il gruppo “Sensore” e il gruppo “Attore“. L’obiettivo per tutti è guidare un cursore su uno schermo verso un bersaglio. Semplice? Non proprio.
Ecco il trucco:
- Il gruppo Sensore può vedere sia il cursore che il bersaglio finale, ma non ha modo di muovere direttamente il cursore. La loro unica “arma”? Premere dei pulsanti che muovono un *secondo* bersaglio, visibile solo al gruppo Attore. Ogni sensore, premendo il suo pulsante, sposta questo secondo bersaglio in una direzione specifica, ma all’inizio nessuno sa quale!
- Il gruppo Attore, invece, può muovere il cursore (quello vero, visibile anche ai Sensori), ma… non può vedere né il cursore stesso né il bersaglio finale! L’unica cosa che vedono è quel secondo bersaglio mosso dai Sensori. Il loro compito è raggiungere *quel* bersaglio mobile. Anche qui, ogni attore ha un pulsante che sposta il cursore in una direzione specifica e sconosciuta all’inizio.
In pratica, i Sensori devono capire come “guidare” gli Attori dando loro degli obiettivi intermedi (il secondo bersaglio), e gli Attori devono imparare a seguire questi segnali muovendo il cursore comune. Il tutto senza potersi parlare e senza sapere inizialmente quale sia il proprio specifico “potere” (la direzione associata al proprio pulsante). Una vera sfida di coordinazione gerarchica e apprendimento al buio! L’esperimento è stato chiamato “Nested Neuron Game” (Gioco del Neurone Annidato), perché è come se il gruppo Attore giocasse una versione del gioco originale all’interno del gioco più grande gestito dai Sensori.
Come Hanno Imparato a Collaborare?
La cosa incredibile è che, nonostante la difficoltà, i gruppi umani ci sono riusciti! All’inizio, ovviamente, era il caos. Ma col tempo, le prestazioni sono migliorate. Come l’hanno misurato?
- Tasso di Miglioramento: Hanno visto quante volte le azioni del gruppo avvicinavano effettivamente il cursore al bersaglio. Questo tasso è aumentato significativamente nel tempo per entrambi i gruppi.
- Risposte Corrette Individuali: Hanno analizzato se le singole pressioni dei pulsanti (o il non premerli) fossero la scelta giusta in quel momento per avvicinarsi al bersaglio, indipendentemente dagli altri. Anche qui, i giocatori sono diventati più bravi.
- Specializzazione: All’inizio i giocatori reagivano un po’ a caso, ma col tempo hanno imparato a premere il pulsante solo quando il bersaglio era in una direzione specifica, quella che potevano influenzare meglio. La “varianza” degli stimoli a cui reagivano è diminuita, segno di specializzazione.
- Sincronia e Cooperazione: Hanno misurato la correlazione tra le azioni dei giocatori nello stesso gruppo. Come previsto, i giocatori con “poteri” simili (direzioni vicine) tendevano ad agire insieme più spesso di quelli con poteri opposti. Un segno chiaro di cooperazione emergente!

Un altro dato interessantissimo è l’informazione mutua tra lo stato visto dai Sensori (la posizione del vero bersaglio) e le azioni degli Attori. All’inizio era quasi zero, ma poi è cresciuta rapidamente, indicando che i Sensori stavano imparando a comunicare efficacemente la direzione giusta agli Attori. C’era anche un piccolo ritardo (circa mezzo secondo) tra il segnale dei Sensori e la reazione degli Attori, il tempo necessario perché l’informazione “viaggiasse” e venisse elaborata.
Capire il “Come”: I Modelli Computazionali
Ok, i gruppi umani ci riescono, ma *come* fanno? Quali processi mentali o strategie usano? Per capirlo, i ricercatori hanno usato dei modelli computazionali, simulando il comportamento dei giocatori con diversi tipi di “agenti” artificiali.
Due modelli si sono rivelati particolarmente efficaci nel replicare il comportamento umano:
- Apprendimento Bayesiano (Thompson Sampling): Immaginate ogni giocatore come un piccolo scienziato che formula ipotesi. Questo modello simula agenti che mantengono una “credenza” (una probabilità) sull’effetto delle proprie azioni e la aggiornano continuamente in base a ciò che osservano. Anche se l’osservazione è rumorosa (perché altri agiscono contemporaneamente), col tempo riescono a capire il proprio ruolo e agire di conseguenza. È un approccio basato su “modelli interni”: gli agenti si costruiscono una rappresentazione di come funzionano le cose.
- Razionalità Limitata: Questo modello vede i giocatori come decisori che cercano di fare del loro meglio, ma con risorse cognitive limitate. Non sono perfettamente razionali, ma ottimizzano date le loro capacità. Anche questo modello ha riprodotto bene i dati umani, descrivendo l’interazione come una rete complessa e “loopy” (con cicli di feedback) di decisioni.
La cosa forse più sorprendente è stata scoprire quali modelli *non* funzionavano. I modelli basati sull’Apprendimento per Rinforzo Gerarchico (un approccio molto popolare nell’intelligenza artificiale, dove un “capo” dà ordini e ricompense ai “subordinati”) hanno fallito miseramente! Perché? Sembra che questi modelli facciano fatica con il rumore (le azioni imperfette degli altri giocatori), i ritardi nel feedback (specialmente per i Sensori, che vedono l’effetto delle loro azioni solo dopo la reazione degli Attori) e soprattutto con la necessità di un’ottimizzazione concorrente e simultanea. Nel gioco, Sensori e Attori imparano e si adattano *allo stesso tempo*, non in fasi separate come spesso assunto dai modelli gerarchici classici. Questo fallimento evidenzia l’importanza dei modelli interni (come quello Bayesiano) per gestire l’incertezza e coordinarsi in modo flessibile.
Collegamenti con Idee più Grandi: Cervelli, Controllo e Cooperazione
Questa ricerca non è solo un gioco. Tocca corde profonde su come funzionano i sistemi complessi, dal nostro cervello alle società.
Un parallelo affascinante è con la Teoria del Controllo Percettivo (PCT). Questa teoria suggerisce che il nostro comportamento non è una semplice reazione a stimoli, ma un processo continuo per mantenere le nostre percezioni in linea con i nostri obiettivi (o “valori di riferimento”). La PCT immagina una gerarchia di sistemi di controllo annidati: i livelli superiori stabiliscono obiettivi astratti, mentre quelli inferiori gestiscono i dettagli motori per raggiungerli, il tutto basato su feedback locale. Il Nested Neuron Game sembra proprio un piccolo sistema PCT in azione! I Sensori (livello alto) impostano il riferimento (il bersaglio per gli Attori), e gli Attori (livello basso) agiscono per minimizzare l’errore percepito localmente, senza bisogno di conoscere l’obiettivo finale o cosa facciano esattamente i Sensori. Ognuno controlla il proprio “piccolo mondo”.
Questo ricorda anche come funziona il cervello: miliardi di neuroni specializzati che collaborano senza che nessuno abbia la visione d’insieme. O come in economia, nel modello di leadership di Stackelberg, dove un “leader” anticipa la reazione del “follower”. O persino come in alcune reti neurali artificiali (target propagation), dove l’apprendimento avviene localmente in ogni strato.
E se Costruissimo “Cervelli” più Complessi?
I ricercatori si sono spinti oltre. E se i gruppi fossero più grandi? E se ci fossero più “strati” gerarchici, come un Sensore che guida un Attore che a sua volta guida un altro Attore? Hanno usato simulazioni evolutive, lasciando che le reti di agenti (basati sul modello Thompson) mutassero e si evolvessero per diventare più efficienti nel gioco.
I risultati? Le reti più complesse, con più agenti e talvolta più strati, spesso imparavano più velocemente! Sorprendentemente, anche un po’ più di “rumore” (azioni casuali degli agenti) a volte aiutava la performance complessiva. Questo suggerisce che, almeno per questo tipo di compito, aumentare la complessità e la ridondanza può essere vantaggioso, proprio come nel cervello, dove molti neuroni rumorosi collaborano per produrre un comportamento coerente.
Cosa Ci Portiamo a Casa?
Questo studio, partito da un setup sperimentale quasi ludico, ci offre spunti preziosi sulla coordinazione umana (e forse non solo). Ci dice che:
- La coordinazione efficace tra gruppi specializzati può emergere senza comunicazione esplicita, basandosi sull’apprendimento reciproco.
- Avere modelli interni (anche impliciti) di come funzionano le cose e di come gli altri potrebbero reagire sembra cruciale, specialmente in ambienti rumorosi e con feedback ritardato.
- L’ottimizzazione concorrente – dove tutti i “pezzi” del sistema imparano e si adattano simultaneamente – potrebbe essere un meccanismo più realistico per la coordinazione complessa rispetto ai modelli strettamente gerarchici con scale temporali separate.
- Sistemi complessi possono funzionare efficacemente anche se ogni componente ha solo una visione locale del problema, un po’ come i neuroni nel cervello o gli individui in una grande organizzazione.
Insomma, la prossima volta che vedrete una squadra sportiva muoversi all’unisono, un’orchestra suonare in perfetta armonia, o semplicemente riuscirete a collaborare con qualcuno su un progetto difficile, ricordatevi del Nested Neuron Game. Potrebbe esserci in gioco una danza silenziosa di apprendimento reciproco e ottimizzazione concorrente, un segreto del teamwork che stiamo solo iniziando a decifrare.

Fonte: Springer





