
Cedar: L’AI che Impara dai Tuoi Dispositivi (Senza Spiarti!) Rivoluziona l’IoT Personale
Ciao a tutti! Oggi voglio parlarvi di qualcosa che mi appassiona tantissimo: come rendere i nostri dispositivi intelligenti, quelli che compongono l’Internet of Things (IoT), davvero *personali* e utili per ciascuno di noi, ma senza compromettere la nostra privacy. Sembra una sfida impossibile, vero? Soprattutto oggi, con leggi sempre più stringenti sulla protezione dei dati.
Pensateci: l’Intelligenza Artificiale (AI) ha un potenziale enorme per migliorare la nostra vita quotidiana attraverso l’IoT. Immaginate auto che capiscono il nostro stile di guida per aumentare la sicurezza (Smart Mobility), sistemi che gestiscono prodotti in modo proattivo per la nostra soddisfazione (Smart Economy), o addirittura strumenti che ci aiutano con l’autodiagnosi medica (Smart Healthcare). Fantastico, no?
Il problema è che, tradizionalmente, per addestrare questi modelli AI super intelligenti, si dovevano raccogliere montagne di dati su un server centrale. Ma con le nuove normative sulla privacy (ciao GDPR!), questa strada è diventata impraticabile. I nostri dati personali, quelli che rivelano le nostre abitudini, preferenze, e stati d’animo, devono rimanere… beh, personali!
La Vecchia Strada Non Funziona Più: I Limiti dell’Approccio Centralizzato
Quindi, il vecchio metodo “raccogli tutto al centro” ha due grossi problemi nel mondo dell’IoT personalizzato (che chiameremo PIoT):
- Addestramento Centralizzato Insufficiente: Senza accesso diretto ai dati privati degli utenti, conservati sui loro dispositivi, come si fa ad addestrare modelli AI potenti ed efficaci? La qualità e la quantità dei dati sono fondamentali, ma la privacy crea delle vere e proprie “isole” di dati (data silos) che impediscono la condivisione e l’aggregazione necessarie.
- Personalizzazione Diventa Cruciale (e Difficile): Un modello AI generico, addestrato su dati aggregati (ammesso che si possano ottenere), difficilmente sarà perfetto per *me* o per *voi*. La vera magia sta nell’adattare il modello alle esigenze specifiche di ogni individuo, usando proprio quei dati privati che non possono lasciare il dispositivo. Serve un modo per personalizzare l’AI localmente.
Federated Learning: Un Passo Avanti, Ma Non Ancora la Soluzione Definitiva
Per superare questi ostacoli, è nata un’idea brillante: il Federated Learning (FL). Invece di mandare i dati al server, ogni dispositivo addestra un modello localmente, usando i propri dati privati. Poi, solo i parametri del modello (non i dati!) vengono inviati a un server centrale che li aggrega per creare un modello globale migliore. Sembra perfetto, no? Privacy salva, intelligenza collettiva!
Purtroppo, anche l’FL ha le sue gatte da pelare, specialmente nel contesto variegato e complesso del PIoT:
- Eterogeneità dei Dati: I dati su ogni dispositivo sono diversi (Non-IID – non indipendenti e identicamente distribuiti). Io uso il mio smartphone in modo diverso da voi, i miei sensori raccolgono dati diversi. Questa eterogeneità rende difficile per l’FL creare un modello globale che funzioni bene per tutti e che sia facilmente personalizzabile. Si rischia di imparare molto bene dalle situazioni più comuni, trascurando quelle più rare ma importanti.
- Costi di Comunicazione: Anche se non si inviano i dati grezzi, scambiare continuamente i parametri dei modelli tra dispositivi e server può essere costoso in termini di banda e batteria, soprattutto su reti non sempre performanti come quelle usate dall’IoT.
- Vulnerabilità di Sicurezza: Le comunicazioni avvengono su reti aperte (Internet!). Utenti malintenzionati potrebbero provare a “indovinare” i dati originali analizzando i parametri del modello (data inversion) o potrebbero inviare aggiornamenti “avvelenati” per sabotare il modello globale (model poisoning). La privacy promessa dall’FL diventa fragile.

Ecco Cedar: L’Anello Mancante che Unisce Intelligenza, Privacy ed Efficienza
Ed è qui che entra in gioco il protagonista della nostra storia: Cedar. Ho lavorato allo sviluppo di questo framework, ed è una vera svolta! Cedar è progettato specificamente per superare le sfide dell’FL nel PIoT, rendendo l’AI personalizzata una realtà sicura, efficiente ed efficace.
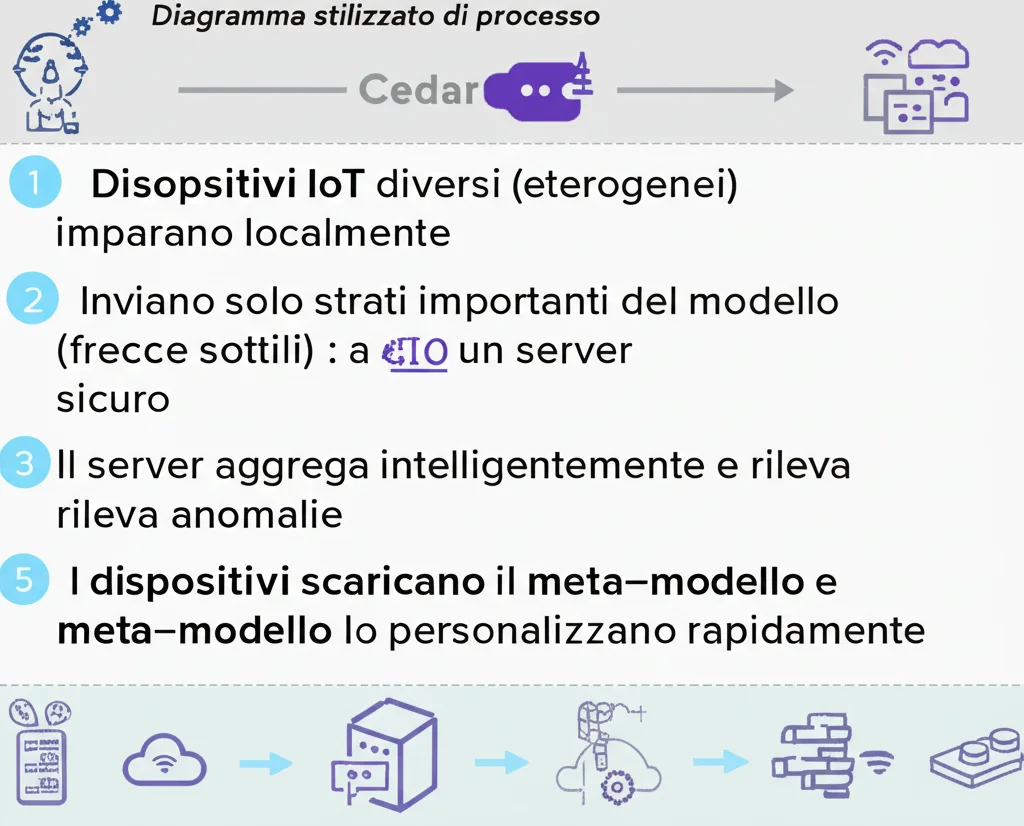
Come ci riesce? Cedar combina in modo intelligente il Federated Learning con un’altra tecnica potentissima: il Meta-Learning. Potete pensare al Meta-Learning come “imparare ad imparare”. Invece di creare solo un modello globale generico, Cedar crea un meta-modello globale. Questo meta-modello racchiude una conoscenza più profonda e generalizzabile, estratta dalla diversità dei dati locali, ed è progettato per essere adattato *rapidamente* e *facilmente* da ogni singolo dispositivo alle proprie esigenze specifiche.
I Superpoteri di Cedar: Come Funziona in Pratica?
Cedar non è solo un’idea, è un framework concreto con funzioni specifiche per affrontare ogni sfida:
- Gestione dell’Eterogeneità (Grazie al Meta-Learning): Cedar permette ai dispositivi di estrarre la “conoscenza strutturale” dai loro dati eterogenei. Questa conoscenza viene poi combinata nel meta-modello globale, che diventa incredibilmente bravo a generalizzare e trasferire l’apprendimento. Quando un dispositivo scarica questo meta-modello, può personalizzarlo velocemente usando pochissimi dati locali.
- Efficienza dei Costi (Aggiornamenti Intelligenti): Invece di inviare l’intero modello locale al server ad ogni round, Cedar è furbo! Identifica e invia solo gli strati (layers) del modello che contengono le informazioni più significative per quell’aggiornamento. Questo riduce drasticamente i costi di comunicazione e accelera la convergenza, senza sacrificare la qualità. È un po’ come mandare un riassunto invece dell’intero libro!
- Sicurezza Robusta (Difesa Contro gli Attacchi): Cedar integra meccanismi di sicurezza avanzati. Durante l’invio dei modelli locali (che sono già “parziali” grazie all’upload a strati), prepara modelli “asimmetrici” che rendono quasi impossibile ricostruire i dati originali (addio data inversion!). Inoltre, il server analizza gli aggiornamenti ricevuti, individua quelli sospetti o “avvelenati” (addio model poisoning!) e li gestisce in modo da non compromettere il meta-modello globale.
- Personalizzazione Ottimale: Il risultato finale è un meta-modello globale potente e sicuro, pronto per essere scaricato da qualsiasi dispositivo PIoT. Bastano pochi passi di “fine-tuning” locale sui dati privati dell’utente per ottenere un modello personalizzato che offre prestazioni ottimali per le sue specifiche esigenze e contesti applicativi.
Alla Prova dei Fatti: Cedar Batte la Concorrenza!
Ok, belle parole, ma funziona davvero? Assolutamente sì! Abbiamo messo Cedar alla prova utilizzando ben dodici dataset standard che rappresentano tre tipi di compiti tipici del PIoT: regressione su dati strutturati, classificazione di testi e classificazione di immagini. Abbiamo confrontato Cedar con cinque metodi di riferimento (baseline) ben noti nel campo del Federated Learning (FedAvg, FedFomaml, FedReptile, FedMeta-MAML, FedMeta-SGD).
I risultati sono stati… beh, lasciatemelo dire, impressionanti!
- Migliore Efficienza e Velocità: Cedar ha dimostrato di addestrare i modelli più velocemente, con curve di apprendimento più stabili e raggiungendo prestazioni superiori in meno round di comunicazione rispetto ai metodi tradizionali.
- Gestione Superiore dell’Eterogeneità: Sia con dati molto diversi tra i client (alta eterogeneità) che con dati più simili (bassa eterogeneità), Cedar ha mantenuto prestazioni elevate e stabili, dimostrando la sua capacità di estrarre conoscenza utile anche da situazioni complesse. Ha funzionato alla grande anche quando solo una piccola parte dei dispositivi partecipava all’addestramento.
- Adattamento Rapidissimo: La vera magia si vede nella fase di personalizzazione. I modelli generati da Cedar possono essere adattati localmente con pochissimi dati e in pochissimi round (spesso solo 10!), raggiungendo prestazioni personalizzate nettamente superiori rispetto ai modelli ottenuti con altri metodi. Abbiamo visto miglioramenti medi del 19.48% in questa fase!
- Risparmio sui Costi: Grazie all’upload selettivo degli strati, Cedar ha ridotto significativamente la quantità di dati da trasmettere in ogni round (fino al 23% in meno in alcuni casi!), raggiungendo prestazioni migliori con budget di comunicazione inferiori e in meno tempo. Ad esempio, in alcuni test, ha raggiunto l’obiettivo di accuratezza quasi il 98% più velocemente del migliore tra i concorrenti!
- Sicurezza Blindata: Nei test contro gli attacchi, Cedar si è dimostrato un osso duro. Ha reso praticamente impossibile ricostruire i dati privati dagli aggiornamenti del modello (le immagini ricostruite erano puro “rumore”, molto meglio dei metodi basati su Differential Privacy o altri). E contro gli attacchi di “label flipping” (dove i client malintenzionati cercano di ingannare il modello cambiando le etichette dei dati), Cedar ha mantenuto il tasso di successo dell’attacco (ASR) bassissimo, con miglioramenti fino al 62% rispetto ad altre tecniche di difesa.

Cosa Significa Tutto Questo per il Futuro dell’IoT?
Cedar non è solo un esercizio accademico. Rappresenta un passo avanti fondamentale per sbloccare il vero potenziale dell’AI nell’Internet of Things personalizzato. Significa poter avere:
- Dispositivi che imparano e si adattano a noi in modo continuo e sicuro.
- Servizi PIoT più intelligenti ed efficienti in tutti i domini (salute, mobilità, casa, lavoro…).
- Maggiore fiducia nella tecnologia, sapendo che la nostra privacy è protetta.
- Un ecosistema AI più democratico, dove anche i dispositivi con risorse limitate possono contribuire e beneficiare dell’intelligenza collettiva.
Certo, c’è sempre spazio per migliorare. Stiamo già pensando a come rendere Cedar ancora più robusto alla variabilità dei dispositivi fisici, alle connessioni di rete instabili, a nuovi tipi di attacchi e a come integrare modelli ancora più potenti come i Large Language Models (LLMs) per gestire dati multimodali. Ma la strada è tracciata.
In conclusione, Cedar dimostra che è possibile avere la botte piena (AI potente e personalizzata) e la moglie ubriaca (privacy e sicurezza garantite). È un framework che orchestra le risorse distribuite nel continuum cloud-edge-device in modo efficiente e sicuro, aprendo le porte a una nuova era di interazione uomo-macchina davvero intelligente e rispettosa della nostra individualità. Il futuro dell’IoT personalizzato è più vicino (e più sicuro) grazie a Cedar!
Fonte: Springer





