AI e Feedback Universitario: Decifrare le Emozioni degli Studenti con il Machine Learning Avanzato
Avete mai pensato a quanto sia incredibilmente prezioso il feedback che gli studenti danno ai loro docenti? È una miniera d’oro! Non solo aiuta i professori a capire cosa funziona e cosa no, ma plasma l’intera esperienza di apprendimento. Ma come possiamo analizzare montagne di commenti scritti in modo efficace? Qui entro in gioco io, o meglio, entra in gioco la tecnologia che mi appassiona: l’analisi del sentiment potenziata dal machine learning.
Immaginate di poter “leggere tra le righe” di centinaia, migliaia di feedback, capendo non solo *cosa* dicono gli studenti, ma *come* si sentono riguardo a un corso o a un docente. È proprio questo che fa l’analisi del sentiment: usa algoritmi sofisticati per riconoscere il tono emotivo – positivo, negativo o neutro – nascosto nel testo. È un po’ come avere un superpotere per decifrare le percezioni e le opinioni!
Perché Analizzare il Sentiment del Feedback è Cruciale?
Pensateci: un feedback positivo è una pacca sulla spalla virtuale. Ci dice che le metodologie didattiche stanno funzionando, che il materiale è chiaro, che l’atmosfera in aula è buona. È un segnale per continuare su quella strada, magari con piccoli aggiustamenti.
Ma è il feedback con sentiment negativo che spesso offre le opportunità di crescita più grandi. Magari gli studenti si sentono sopraffatti dal ritmo, trovano i materiali troppo complessi, o desiderano più supporto. Queste non sono critiche fini a se stesse, sono indicazioni preziose! Grazie all’analisi del sentiment, possiamo individuare esattamente questi punti dolenti e riflettere su come adattare l’insegnamento. Potremmo rallentare, introdurre sessioni più interattive, fornire risorse extra, o esplorare nuovi metodi didattici come il project-based learning o discussioni di gruppo.
A livello istituzionale, analizzare questi dati su larga scala permette di:
- Identificare problemi ricorrenti che impattano sulla soddisfazione e sul rendimento degli studenti.
- Capire dove i docenti eccellono e dove potrebbero aver bisogno di supporto o formazione specifica (ad esempio, sulle capacità comunicative o sul coinvolgimento).
- Promuovere una cultura della trasparenza e del miglioramento continuo, mostrando agli studenti che la loro voce viene ascoltata e usata per migliorare davvero le cose.
La pratica riflessiva, alimentata da un feedback ben compreso (sia quantitativo che qualitativo), è fondamentale per preparare gli studenti al mondo del lavoro. Sebbene i questionari a crocette (quantitativi) siano facili da analizzare, sono i commenti aperti (qualitativi) che spesso contengono le sfumature più ricche. Ed è qui che l’analisi del sentiment diventa la nostra alleata strategica, superando la difficoltà di analizzare manualmente grandi volumi di testo libero.
Come Abbiamo Affrontato la Sfida: Metodologia e Modelli ML
Nel nostro viaggio esplorativo, abbiamo preso in esame ben 5000 risposte di studenti di ingegneria. Perché ingegneria? Perché spesso hanno carichi di studio intensi e aspettative elevate, rendendo il loro feedback particolarmente significativo. Raccogliere questi dati da varie fonti (questionari online, form dedicati, ecc.) non è stato un gioco da ragazzi, soprattutto per standardizzare il formato.
Il passo successivo è stato trasformare queste parole in qualcosa che un computer potesse capire. Abbiamo usato una tecnica chiamata TF-IDF (Term Frequency-Inverse Document Frequency). Sembra complicato, ma l’idea è semplice: dare più peso alle parole che sono frequenti in un singolo feedback ma rare nell’intero dataset. Parole come “interessante” o “deludente” ottengono un punteggio alto, mentre parole comuni come “il” o “corso” vengono ridimensionate. È un modo furbo per far emergere i termini carichi di sentiment.
Una volta preparati i dati, abbiamo messo alla prova cinque diversi “cervelli” di machine learning, scelti per la loro diversità nell’approcciare il problema:
- Support Vector Machine (SVM): Cerca il miglior “confine” per separare i feedback positivi, negativi e neutri. Abbiamo testato sia la versione lineare (Linear SVC) che quella non lineare (con kernel RBF).
- Random Forest (RF): Immaginate un comitato di esperti (tanti alberi decisionali) che votano per decidere il sentiment. È noto per la sua robustezza.
- Stochastic Gradient Descent (SGD): Un approccio efficiente che impara “passo dopo passo”, ottimizzandosi su ogni feedback che analizza. Ottimo per grandi dataset.
- Multilayer Perceptron (MLP): Una rete neurale artificiale, simile a come pensiamo funzioni il nostro cervello, con strati di “neuroni” che imparano pattern complessi.
- Multinomial Naive Bayes (MNB): Un modello probabilistico più semplice, spesso usato per la classificazione del testo, che si basa sulla frequenza delle parole.
Per ciascun modello, abbiamo “allenato” l’algoritmo su una parte dei dati (l’80%) e poi lo abbiamo testato sulla parte rimanente (il 20%) per vedere quanto fosse bravo a classificare feedback mai visti prima. Abbiamo misurato le loro performance usando metriche standard come accuratezza, precisione, recall e F1-score.
I Risultati: Chi Ha Vinto la Sfida del Sentiment?
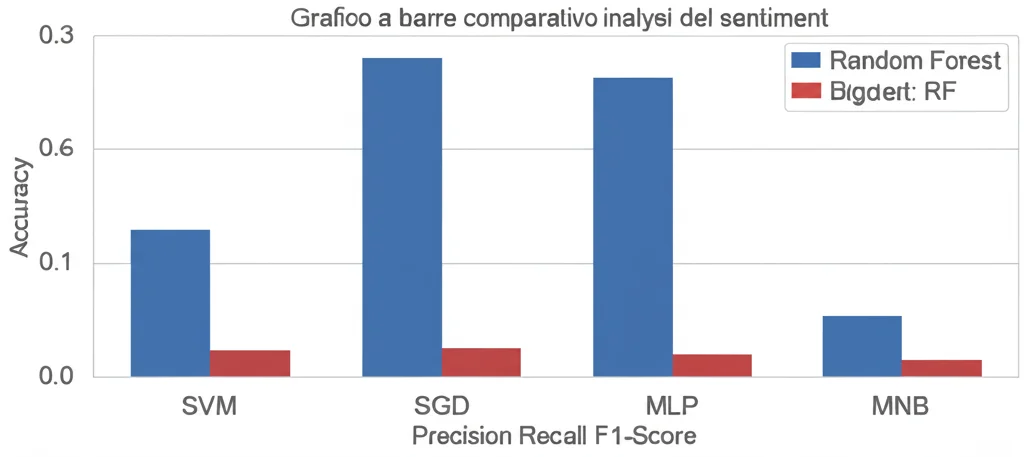
E il vincitore è… Random Forest (RF)! Questo modello si è distinto nettamente, raggiungendo risultati impressionanti:
- Accuratezza: 91% (ha classificato correttamente il 91% dei feedback)
- Precisione: 94% (quando prevedeva un sentiment positivo, era corretto il 94% delle volte)
- Recall: 85% (ha identificato l’85% di tutti i feedback effettivamente positivi)
- F1-Score: 89% (un ottimo bilanciamento tra precisione e recall)
Anche il Support Vector Classifier (SVC), specialmente nella sua versione lineare, ha mostrato performance molto solide, con un’accuratezza dell’87% e un F1-Score dell’87%. Questo conferma la sua efficacia nel gestire dati testuali complessi.
Gli altri modelli, pur fornendo risultati rispettabili (SGD e MLP con F1-Score dell’83%, MNB con il 76%), non hanno raggiunto le vette di RF e SVC. Il modello Naive Bayes, in particolare, pur avendo un’alta precisione, ha mostrato un recall molto più basso (64%), indicando che “perdeva” molti dei feedback positivi.
Perché Random Forest ha funzionato così bene? Probabilmente grazie alla sua natura “di squadra” (ensemble learning): combinando le previsioni di molti alberi decisionali, riduce il rischio di errori e cattura meglio le sfumature del linguaggio. È anche molto bravo a gestire dataset con tante “dimensioni” (come quelli derivati dal TF-IDF) e risulta robusto al “rumore” presente nei dati reali.
Cosa Ci Portiamo a Casa e Sguardi al Futuro
Questa esplorazione ci dimostra che il machine learning, e in particolare modelli sofisticati come Random Forest e SVM, sono strumenti potentissimi per trasformare il feedback degli studenti da semplice testo a insight azionabili. Possiamo andare oltre le medie numeriche e capire davvero le emozioni e le percezioni che guidano l’esperienza educativa.
Le istituzioni possono usare questi strumenti per:
- Monitorare la soddisfazione degli studenti in modo più profondo e tempestivo.
- Fornire ai docenti feedback più mirati per il loro sviluppo professionale.
- Prendere decisioni basate sui dati per migliorare i corsi e i programmi.
Il futuro? Ancora più affascinante! La ricerca si sta muovendo verso:
- Analisi del Sentiment Contestuale e Basata sugli Aspetti (ABSA): Capire non solo se un feedback è positivo o negativo, ma *riguardo a cosa* (es. “la spiegazione era chiara” – positivo sull’aspetto ‘spiegazione’).
- Rilevamento della Severità: Distinguere tra una critica costruttiva e un commento fortemente negativo.
- Modelli Trasformer (come BERT): Algoritmi ancora più avanzati per comprendere il contesto e le sfumature del linguaggio naturale.
- Dashboard AI Interattive: Strumenti che mostrano in tempo reale i trend del sentiment, permettendo interventi rapidi.
- Analisi Multilingue e Cross-Culturale: Adattare questi modelli a contesti educativi globali.

Insomma, l’analisi del sentiment applicata al feedback universitario non è solo un esercizio tecnico, ma un passo fondamentale verso un’istruzione più empatica, reattiva ed efficace. Ascoltare davvero la voce degli studenti, con l’aiuto dell’intelligenza artificiale, è la chiave per costruire un ambiente di apprendimento migliore per tutti.
Fonte: Springer