Adattamento Dominio Multi-Sorgente Senza Dati: La Magia dell’IA che Impara nel Rispetto della Privacy
Ciao a tutti gli appassionati di Intelligenza Artificiale e Machine Learning! Oggi voglio parlarvi di una sfida davvero intrigante nel nostro campo: l’adattamento di dominio (Domain Adaptation). Immaginate di allenare un modello AI super performante su un set di dati, diciamo delle immagini di prodotti prese da un sito web. Poi, provate a usare lo stesso modello su immagini simili ma provenienti da un contesto diverso, magari foto scattate con uno smartphone in condizioni di luce variabili. Spesso, le prestazioni crollano! Questo perché il modello non riesce a generalizzare bene tra “domini” (cioè set di dati con caratteristiche diverse).
Qui entra in gioco l’adattamento di dominio, una tecnica che cerca di trasferire la conoscenza appresa da uno o più domini “sorgente” (dove abbiamo dati etichettati) a un dominio “target” (dove i dati non sono etichettati o lo sono solo in parte). In particolare, l’adattamento di dominio non supervisionato multi-sorgente (UMDA) è molto potente, perché sfrutta dati da *diverse* fonti per migliorare le prestazioni sul target.
Il Problema Nascosto: Privacy e Praticità
Fin qui tutto bello, vero? Peccato che la maggior parte dei metodi UMDA tradizionali dia per scontato un dettaglio non da poco: la possibilità di accedere liberamente e direttamente ai dati di tutti i domini sorgente durante la fase di adattamento. Pensateci un attimo: cosa succede se questi dati contengono informazioni sensibili? Ad esempio, nel riconoscimento facciale o in ambito medico, condividere i dati sorgente originali è spesso impossibile per questioni di privacy.
Inoltre, ci sono questioni pratiche:
- I dataset sorgente possono essere enormi (video, immagini ad alta risoluzione), rendendo il trasferimento e l’archiviazione complessi e costosi.
- A volte, per policy aziendali o accordi legali, i dati semplicemente non possono essere condivisi.
- In scenari di deployment in tempo reale, ri-allenare usando l’intero dataset sorgente può essere computazionalmente proibitivo.
Questi metodi tradizionali, che spesso calcolano le differenze tra le distribuzioni dei dati sorgente e target “coppia per coppia”, diventano impraticabili. C’è bisogno di un approccio diverso, uno che funzioni anche senza avere i dati sorgente a portata di mano durante l’adattamento. È quello che chiamiamo scenario source-free (senza sorgente).
La Nostra Soluzione: TSDA – Adattamento Basato su Campioni “Fidati”
Ed è proprio qui che entra in gioco il nostro lavoro! Abbiamo sviluppato un metodo chiamato TSDA (Trust center Sample-based Source-free Domain Adaptation). L’idea di base è semplice ma potente: invece di usare i dati sorgente, sfruttiamo i modelli già allenati su quei dati. Questi modelli pre-allenati contengono già la conoscenza estratta dai domini sorgente.
Come funziona TSDA? Ecco i passi chiave:
1. Partiamo dai Modelli Sorgente: Abbiamo a disposizione solo i modelli allenati sui vari domini sorgente. Niente dati originali.
2. Cerchiamo i Campioni “Fidati” nel Target: Usiamo i modelli sorgente per analizzare i dati del dominio target (quelli senza etichetta). Calcoliamo l’entropia per ogni campione target. L’entropia, in parole povere, misura l’incertezza della previsione del modello. I campioni target su cui i modelli sorgente sono *molto sicuri* (bassa entropia) sono probabilmente classificati correttamente. Questi li chiamiamo “campioni centro fidati” (trust center samples). Ne selezioniamo uno per ogni classe possibile, quello con l’entropia più bassa in assoluto.
3. Assegnamo Pseudo-Etichette: Questi pochi campioni fidati, però, non bastano per allenare un buon modello target. Quindi, li usiamo come riferimento. Per ogni altro campione target, calcoliamo quanto è simile (usando la similarità coseno nello spazio delle feature estratte) ai vari campioni fidati. Assegniamo al campione target l’etichetta (“pseudo-etichetta”) del campione fidato a cui assomiglia di più. È una strategia di auto-apprendimento (self-supervised pseudo-labeling).
4. Alleniamo Modelli Target: Ora che abbiamo delle etichette (anche se “pseudo”) per i dati target, possiamo allenare dei modelli specifici per il dominio target, partendo dai modelli sorgente pre-allenati. Ne alleniamo uno per ogni modello sorgente originale.
5. Integrazione Intelligente: Non tutti i domini sorgente sono ugualmente utili per il target. Alcuni potrebbero essere più simili, altri meno. Invece di dare a tutti lo stesso peso, il nostro metodo impara dei pesi di contribuzione. Usiamo una piccola rete neurale (un Multi-Layer Perceptron) che, basandosi sull’entropia delle previsioni dei vari modelli target su un dato campione, decide quanto “fidarsi” di ciascun modello sorgente per quel campione specifico. La previsione finale è una media pesata delle previsioni dei singoli modelli target.

Perché TSDA Funziona Meglio (Secondo Noi)?
Ci sono diversi motivi per cui crediamo che TSDA sia un passo avanti:
* Privacy Garantita: Non usiamo mai i dati sorgente originali durante l’adattamento. Solo i modelli pre-allenati.
* Praticità: Evitiamo i problemi di trasferimento e archiviazione di grandi dataset.
* Robustezza Migliorata: Il nostro approccio basato sui campioni fidati selezionati tramite entropia si è dimostrato più robusto, specialmente contro gli “attacchi avversari” (adversarial examples). Questi sono piccoli disturbi aggiunti ai dati di input, quasi impercettibili per un umano, ma che possono ingannare i modelli AI. Metodi come SHOT o DECISION usano centroidi calcolati sui dati target per assegnare pseudo-etichette, ma questi centroidi possono essere imprecisi, specialmente all’inizio. I nostri “campioni fidati” basati sull’entropia sembrano fornire un ancoraggio più solido.
* Ponderazione Adattiva: L’integrazione pesata dei modelli permette di dare più importanza alle fonti più rilevanti per il dominio target, migliorando l’accuratezza finale.
Risultati Sperimentali: I Numeri Parlano
Ovviamente, non ci siamo fermati alla teoria. Abbiamo testato TSDA su diversi dataset benchmark molto usati nella comunità scientifica per l’adattamento di dominio:
- Office-Home: Un dataset complesso con 65 classi e 4 domini (Arte, Clipart, Prodotti, Mondo Reale).
- Office-Caltech10: 10 classi comuni tra Office-31 e Caltech-256, con 4 domini (Amazon, Caltech, DSLR, Webcam).
- Office31: Un classico con 31 classi e 3 domini (Amazon, Webcam, DSLR).
Abbiamo confrontato TSDA con molti altri metodi, sia quelli tradizionali che richiedono i dati sorgente (come MDAN, DCTN, M³SDA), sia altri metodi source-free più recenti (come MA, SHOT, BAIT, DECISION, Caida, ATEN).
I risultati? Beh, siamo molto soddisfatti! Su Office-Caltech10, ad esempio, abbiamo raggiunto un’accuratezza media del 98.0%, superando tutti i metodi di confronto. Anche sugli altri dataset, TSDA ha mostrato prestazioni molto competitive o superiori, nonostante non avesse accesso ai dati sorgente, a differenza di alcuni metodi con cui ci siamo confrontati.
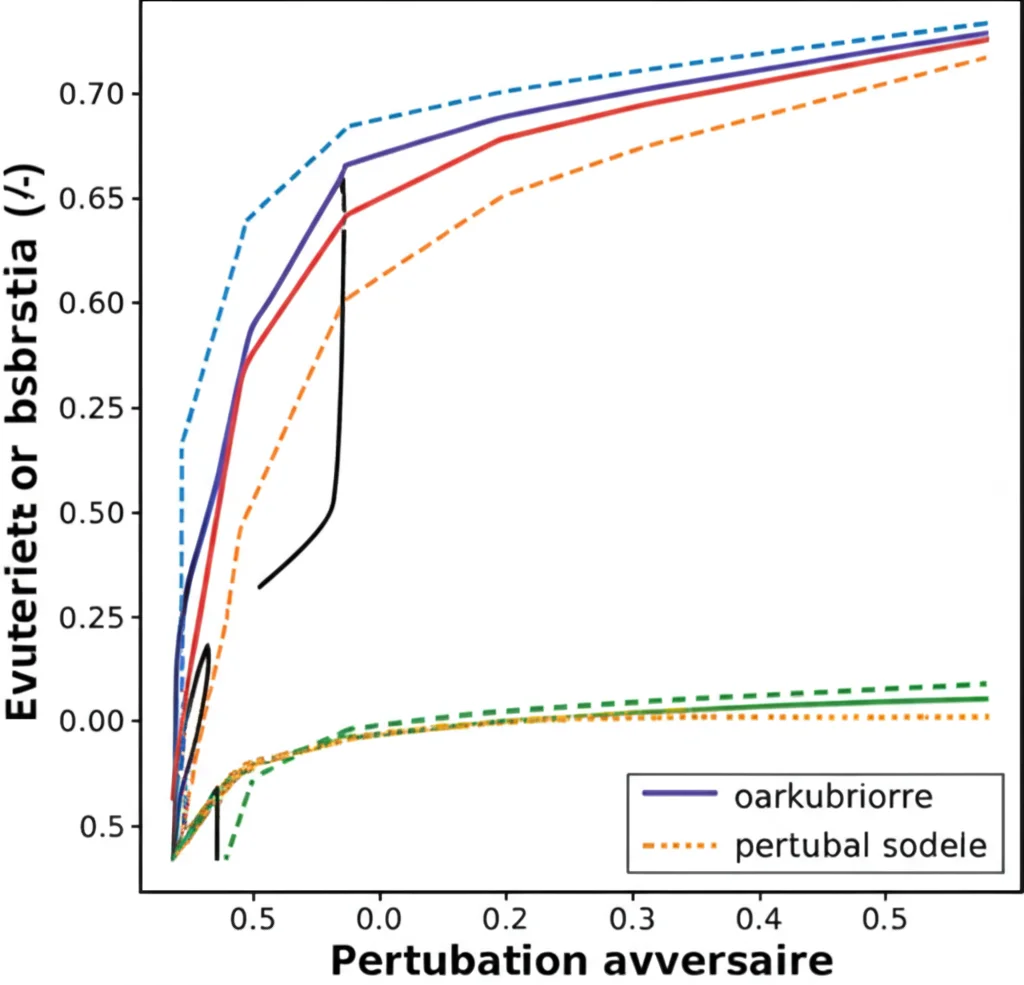
Particolarmente interessante è stato il test di robustezza agli attacchi avversari (generati con PGD). Anche aggiungendo una percentuale significativa di questi esempi “malevoli” ai dati target, TSDA ha mantenuto un’accuratezza superiore rispetto agli altri metodi, confermando che la strategia dei campioni fidati basati sull’entropia aiuta a stabilizzare l’apprendimento.

Abbiamo anche fatto delle analisi specifiche (ablation studies) per verificare l’importanza dei vari componenti del nostro metodo. Ad esempio, abbiamo visto che la nostra strategia di ponderazione adattiva dei modelli sorgente porta a risultati migliori rispetto a una semplice media. Abbiamo anche verificato che selezionare il campione con entropia minima assoluta come “campione fidato” è più efficace che fare una media tra i campioni a bassa entropia.
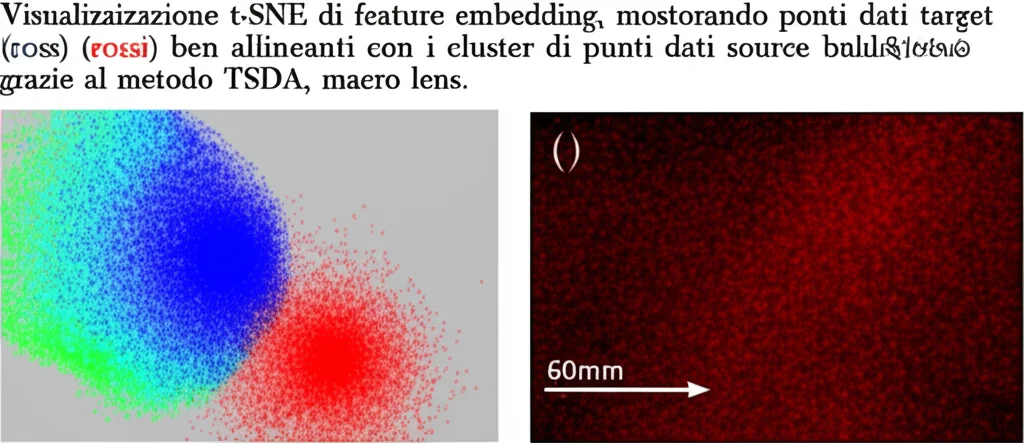
Infine, le visualizzazioni t-SNE (una tecnica per visualizzare dati ad alta dimensionalità in 2D) mostrano chiaramente che le feature estratte dal nostro modello per i dati target sono molto meglio allineate e separate per classe rispetto a un approccio base (“source-only”), indicando un adattamento di dominio efficace.
Limiti e Prospettive Future
Siamo onesti: nessun metodo è perfetto. Anche con TSDA, l’assegnazione di pseudo-etichette può introdurre degli errori, specialmente se la differenza tra domini è molto grande. Un’idea per il futuro è esplorare strategie per selezionare *multipli* campioni fidati per classe, magari usando delle soglie sull’entropia o altre metriche di confidenza, per rendere l’assegnazione delle pseudo-etichette ancora più robusta.
Inoltre, al momento abbiamo testato TSDA principalmente su dataset di immagini. Sarebbe molto interessante estenderlo e valutarlo anche su altri tipi di dati, come il testo.
In Conclusione
L’adattamento di dominio multi-sorgente senza accesso ai dati sorgente è una sfida cruciale per rendere l’IA più pratica, sicura e rispettosa della privacy. Con TSDA, abbiamo proposto un approccio che, sfruttando intelligentemente i modelli pre-allenati e una strategia di pseudo-etichettatura basata su campioni fidati identificati tramite entropia, riesce non solo a risolvere il problema, ma anche a ottenere prestazioni allo stato dell’arte e una maggiore robustezza.
Crediamo che metodi come TSDA aprano la strada a un utilizzo più diffuso ed etico delle tecniche di adattamento di dominio in scenari reali, dove la protezione dei dati è fondamentale. È un passo avanti verso un’IA che impara e si adatta in modo efficace, senza dover necessariamente “vedere” tutto. E questo, secondo me, è davvero affascinante!
Fonte: Springer