
Ponti Intelligenti: Come l’IA Impara a Vedere (Anche Quando Cambia Scena!)
Ciao a tutti! Oggi voglio parlarvi di qualcosa che mi appassiona tantissimo: come l’intelligenza artificiale (IA) sta rivoluzionando il modo in cui ci prendiamo cura delle nostre infrastrutture, in particolare dei ponti. E fidatevi, c’è una sfida tecnologica davvero intrigante di cui voglio raccontarvi.
Sapete, i ponti sono le arterie vitali delle nostre città e nazioni. Garantiscono che persone e merci si muovano in sicurezza. Ma mantenerli in perfetta forma non è uno scherzo. Le ispezioni manuali tradizionali? Spesso lente, costose, soggettive e, diciamocelo, anche un po’ rischiose per gli ispettori. Non è un caso che negli Stati Uniti, ad esempio, la condizione generale dei ponti sia stata definita “mediocre”. C’è bisogno di un cambio di passo!
L’Avvento dell’IA e dei Droni: Una Nuova Era per le Ispezioni
Qui entra in gioco la magia della tecnologia moderna. Pensate a droni agili e leggeri, come l’Elios 2 che abbiamo usato in questo studio, equipaggiati con telecamere ad alta risoluzione. Possono volare vicino alle strutture, raggiungere punti difficili e raccogliere una marea di dati visivi in pochissimo tempo. Fantastico, no?
Ma raccogliere dati è solo metà del lavoro. Come analizziamo questa enorme quantità di immagini in modo rapido ed efficiente? Ecco che scende in campo il deep learning, una branca potentissima dell’IA. Stiamo sviluppando algoritmi capaci di “vedere” e riconoscere automaticamente i diversi elementi di un ponte (travi, piloni, impalcati, ecc.) direttamente dalle immagini. Questo processo si chiama segmentazione semantica ed è fondamentale: ci dà una mappa dettagliata della struttura e apre la strada all’identificazione automatica di eventuali difetti.
Diversi studi hanno già esplorato questa strada, sviluppando reti neurali sempre più sofisticate (come le Fully Convolutional Networks o FCN, e architetture più complesse come StructureNet) per riconoscere i componenti dei ponti, anche in scene complesse o video. Alcuni hanno persino usato l’inferenza Bayesiana per quantificare l’incertezza delle previsioni o tecniche semi-supervisionate per ridurre la necessità di etichettare manualmente tutte le immagini.
Il Tallone d’Achille: Il Problema del “Domain Shift”
Sembra tutto perfetto, vero? Droni che raccolgono dati, IA che li analizza… e invece no. C’è un ostacolo bello grosso che chiamiamo “domain shift”. Immaginate di addestrare la nostra IA a riconoscere le parti di un ponte specifico, magari uno in acciaio con una certa verniciatura, in determinate condizioni di luce. Usiamo migliaia di immagini etichettate (il “source domain”) e l’IA diventa bravissima… su *quel* ponte.
Poi, cosa succede se proviamo a usare la stessa IA su un ponte diverso (“target domain”)? Magari è fatto di un materiale differente, ha un colore diverso, la forma delle travi è leggermente cambiata, o semplicemente l’illuminazione è completamente diversa (pensate a un giorno nuvoloso contro uno soleggiato). L’IA, poverina, va in crisi! Le sue prestazioni crollano drasticamente perché si trova in un “dominio” visivo che non ha mai visto durante l’addestramento.
Questo è il “domain shift”: la differenza tra i dati su cui l’IA è stata addestrata e quelli su cui deve operare nel mondo reale. E nel caso dei ponti, le variazioni possibili sono infinite: forma, dimensione, colore, texture, illuminazione, condizioni ambientali… è impensabile creare un dataset di addestramento che copra *tutte* le possibilità.
Certo, potremmo riaddestrare l’IA con nuove immagini etichettate del ponte “target”. Ma etichettare migliaia di immagini a livello di pixel è un lavoro immane, costoso e richiede tempo prezioso. Non è una soluzione pratica su larga scala.

Le Soluzioni Esistenti: L’Adattamento di Dominio Non Supervisionato (UDA)
Per fortuna, la comunità scientifica non è rimasta a guardare. Esistono tecniche chiamate Unsupervised Domain Adaptation (UDA). L’idea di base è geniale: adattare un modello addestrato sul dominio “source” (con etichette) per farlo funzionare bene sul dominio “target” (senza etichette), cercando di “allineare” le caratteristiche che l’IA impara dai due domini. Spesso si usano approcci “avversariali”: una parte della rete (il generatore/segmentatore) cerca di produrre risultati che ingannino un’altra parte (il discriminatore), la quale cerca di capire se un dato proviene dal dominio source o target. L’obiettivo è rendere i dati dei due domini indistinguibili per il discriminatore, forzando così l’IA a imparare caratteristiche “invarianti” rispetto al dominio.
Queste tecniche UDA sono state usate con successo in vari campi, anche nel monitoraggio strutturale basato su segnali (vibrazioni, accelerazioni) per trasferire modelli da simulazioni a strutture reali, o da una struttura all’altra. Recentemente, sono state applicate anche all’analisi di immagini per rilevare crepe o difetti su superfici.
Tuttavia, nelle nostre indagini preliminari sui ponti, abbiamo notato una cosa: quando il “salto” tra il dominio source e target è molto grande (come spesso accade tra ponti diversi), anche le tecniche UDA più moderne faticano a colmare completamente il divario. Il miglioramento c’è, ma non è ancora sufficiente per garantire l’affidabilità necessaria in un’applicazione critica come l’ispezione dei ponti.
La Nostra Proposta: Potenziare l’UDA con l’Histogram Matching Class-wise (CWHM)
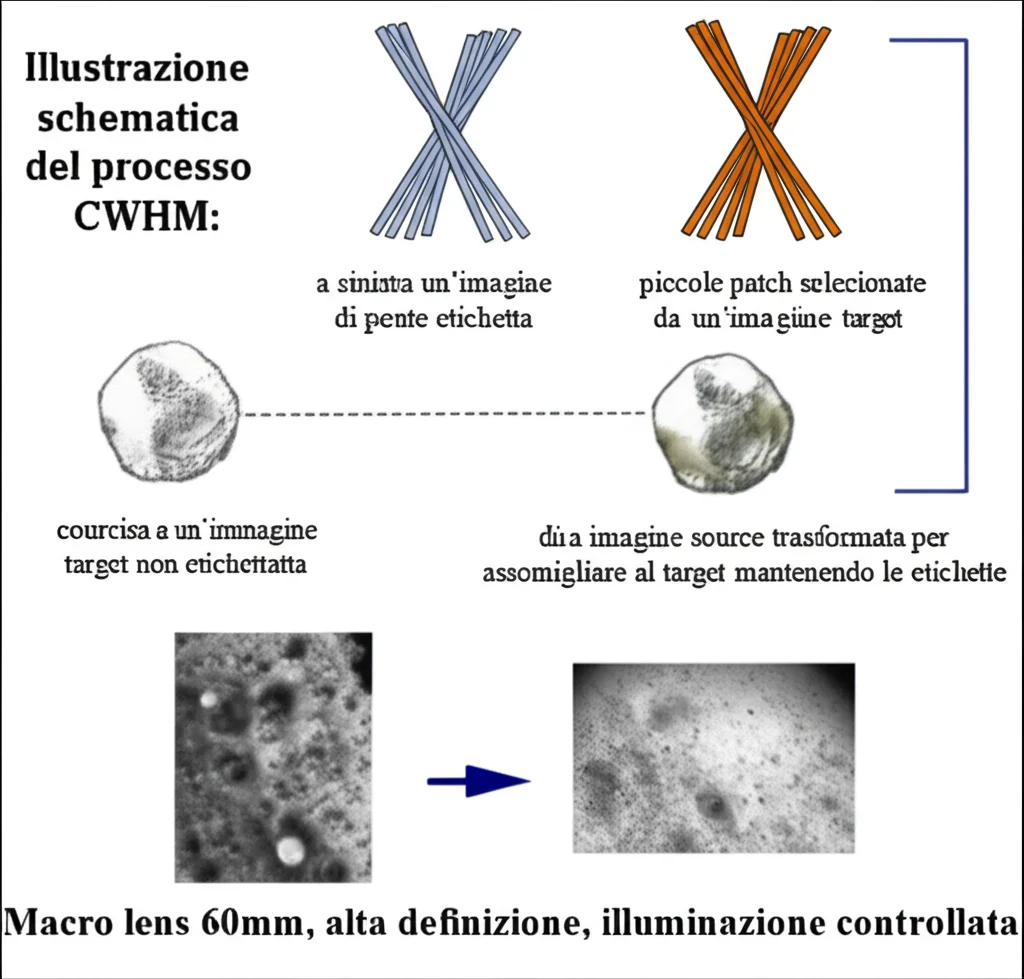
Ed è qui che entra in gioco la nostra idea, il cuore di questo studio. Ci siamo detti: e se potessimo “avvicinare” i due domini *prima* ancora di applicare l’UDA? Se potessimo rendere le immagini del dominio source visivamente più simili a quelle del target, pur mantenendo le etichette originali?
Abbiamo pensato all’histogram matching, una tecnica classica di elaborazione delle immagini che modifica un’immagine sorgente per far sì che la sua distribuzione di intensità dei pixel (il suo “istogramma”) assomigli a quella di un’immagine di riferimento. Ma applicarlo globalmente a tutta l’immagine non funziona bene per i ponti, perché componenti diversi (es. travi e piloni) hanno colori e texture molto differenti.
Così abbiamo sviluppato un approccio Class-wise Histogram Matching (CWHM). Ecco come funziona, in modo semplice:
- Prendiamo un’immagine *non etichettata* dal dominio target.
- Manualmente, selezioniamo rapidamente alcune piccole aree (patch) rappresentative per ogni classe di componente che ci interessa (es. una patch di trave, una di pilone, una di impalcato…). È un’operazione veloce, molto meno faticosa dell’etichettatura completa.
- Prendiamo un’immagine *etichettata* dal dominio source.
- Usando le etichette già disponibili, separiamo i pixel dell’immagine source in base alla classe a cui appartengono (tutti i pixel della trave insieme, tutti quelli del pilone, ecc.).
- Applichiamo l’histogram matching a ciascun gruppo di pixel separatamente, usando come riferimento la patch corrispondente selezionata dall’immagine target (es. i pixel della trave source vengono modificati per assomigliare alla patch della trave target).
- Ricombiniamo i gruppi di pixel modificati per ottenere una nuova immagine “aumentata”. Questa immagine ha la stessa struttura e le stesse etichette dell’immagine source originale, ma il suo aspetto (colori, texture) ora assomiglia molto di più a quello del dominio target!
Questo processo ci permette di creare un sacco di nuovi dati di addestramento “aumentati” con uno sforzo manuale minimo.
Il Framework Completo: HM-UDA
A questo punto, abbiamo il nostro set di dati source originale etichettato, il nostro nuovo set di dati aumentato (source trasformato con CWHM) anch’esso etichettato, e il set di dati target non etichettato. Usiamo tutto questo per addestrare un’architettura UDA (nello specifico, abbiamo usato un approccio basato su DeepLab-v2 con ResNet-101 e adattamento nello spazio di output, simile a quello proposto da Tsai et al.).
Chiamiamo questo framework combinato HM-UDA (Histogram Matching – Unsupervised Domain Adaptation). L’idea è che “pre-adattando” le immagini source con CWHM, rendiamo il lavoro successivo dell’UDA molto più facile, permettendogli di colmare anche i divari di dominio più ampi.
La Prova del Nove: I Case Study
Abbiamo messo alla prova il nostro HM-UDA su dati reali raccolti con droni durante un progetto finanziato dal Dipartimento dei Trasporti USA. Abbiamo usato video da tre ponti a travi in acciaio:
- Source Domain: Ponte VA-14005 in Virginia. Abbiamo addestrato il modello base qui.
- Target Domain 1: Ponte WI-530216 in Wisconsin. Visivamente abbastanza diverso dal source.
- Target Domain 2: Ponte VA-24414 in Virginia. Diverso dal source, e con una particolarità: l’impalcato era coperto da lamiere ondulate di alluminio, introducendo differenze non solo di aspetto ma anche di materiale e geometria.
Abbiamo considerato 5 classi di componenti: trave (girder), traversa (cross-girder), pilone (pier), pulvino (pier cap) e impalcato (deck), più lo sfondo (background).
Abbiamo confrontato tre approcci su ciascun target domain:
1. Source Only: Il modello addestrato solo sul source domain, applicato direttamente al target (per vedere l’effetto del domain shift).
2. UDA: Un metodo UDA di riferimento (basato su Tsai et al. [47]), addestrato con source etichettato e target non etichettato.
3. HM-UDA (il nostro): Il nostro approccio combinato, addestrato con source etichettato, source aumentato con CWHM etichettato, e target non etichettato.
Abbiamo valutato le prestazioni usando metriche standard per la segmentazione: Intersection-over-Union (IoU) media, Precision media e Recall media. L’IoU, in particolare, misura quanto bene le aree predette si sovrappongono a quelle reali.
Risultati Che Parlano Chiaro
I risultati sono stati entusiasmanti!
Come previsto, il modello “Source Only” ha sofferto moltissimo il domain shift, con IoU medie intorno a 0.50-0.51 (un valore basso).
L’approccio UDA standard ha migliorato le cose, portando l’IoU media a circa 0.62-0.66. Un passo avanti, ma ancora lontano dalla perfezione.
E il nostro HM-UDA? Ha fatto un balzo notevole!
- Sul primo target (WI-530216), HM-UDA ha raggiunto un’IoU media di 0.835. Rispetto all’UDA standard, è un miglioramento del 21.2% sull’IoU media!
- Sul secondo target (VA-24414, quello con l’impalcato in alluminio), HM-UDA ha ottenuto un’IoU media di 0.869. Qui il miglioramento rispetto all’UDA standard è stato del 21.3% sull’IoU media!
Anche Precision e Recall hanno mostrato miglioramenti simili, consistenti e significativi. Il nostro approccio è riuscito a gestire molto meglio le differenze di colore, texture e persino le variazioni geometriche e di materiale (come l’impalcato in alluminio), recuperando gran parte delle prestazioni perse a causa del domain shift. Le matrici di confusione (che mostrano come le classi vengono predette) sono tornate ad avere valori alti sulla diagonale, indicando una segmentazione molto più accurata.

Perché Tutto Questo è Importante?
Questa ricerca ha implicazioni pratiche enormi. Il mercato globale dei servizi di ispezione ponti è destinato a crescere esponenzialmente, e l’automazione guidata da IA e robotica sarà fondamentale. Ma due grandi ostacoli sono proprio i costi dell’etichettatura dei dati e la scarsa generalizzabilità dei modelli AI a scenari diversi (il nostro amico domain shift).
Il nostro approccio HM-UDA affronta entrambi i problemi:
- Riduce drasticamente la necessità di etichettare dati nel dominio target, richiedendo solo la selezione rapida di qualche patch di riferimento.
- Migliora significativamente la capacità dei modelli di adattarsi a nuovi ponti e condizioni, rendendo l’IA più robusta e affidabile nel mondo reale.
Crediamo che questo sia un passo importante verso ispezioni visive veramente autonome ed efficienti per le nostre infrastrutture critiche.
Uno Sguardo al Futuro
Certo, il lavoro non finisce qui. Vogliamo testare la robustezza del nostro approccio su salti di dominio ancora più drastici (es. da ponti in acciaio a ponti in cemento armato precompresso). Vogliamo studiare come gestire situazioni in cui nel dominio target compaiono classi di componenti completamente nuove, non viste durante l’addestramento. E, naturalmente, pensiamo di estendere questo approccio ad altre applicazioni cruciali, come il rilevamento automatico di difetti (crepe, corrosione) sui ponti o la ricognizione post-disastro degli edifici.
La strada è ancora lunga, ma siamo convinti che combinare in modo intelligente tecniche di data augmentation come il CWHM con potenti algoritmi di adattamento di dominio sia la chiave per sbloccare il pieno potenziale dell’IA nell’analisi delle infrastrutture civili.
Spero che questo viaggio nel mondo dell’IA per i ponti vi sia piaciuto! È un campo in rapidissima evoluzione e pieno di sfide affascinanti.
Fonte: Springer





